new shelton wet/dry: Thermonator
Belgian man whose body makes its own alcohol cleared of drunk-driving
Many primates produce copulation calls, but we have surprisingly little data on what human sex sounds like. I present 34 h of audio recordings from 2239 authentic sexual episodes shared online. These include partnered sex or masturbation […] Men are not less vocal overall in this sample, but women start moaning at an earlier stage; speech or even minimally verbalized exclamations are uncommon.
Women are less likely to die when treated by female doctors, study suggests
For The First Time, Scientists Showed Structural, Brain-Wide Changes During Menstruation
Grindr Sued in UK for sharing users’ HIV data with ad firms
Inside Amazon’s Secret Operation to Gather Intel on Rivals — Staff went undercover on Walmart, eBay and other marketplaces as a third-party seller called ‘Big River.’ The mission: to scoop up information on pricing, logistics and other business practices.
Do you want to know what Prabhakar Raghavan’s old job was? What Prabhakar Raghavan, the new head of Google Search, the guy that has run Google Search into the ground, the guy who is currently destroying search, did before his job at Google? He was the head of search for Yahoo from 2005 through 2012 — a tumultuous period that cemented its terminal decline, and effectively saw the company bow out of the search market altogether. His responsibilities? Research and development for Yahoo’s search and ads products. When Raghavan joined the company, Yahoo held a 30.4 percent market share — not far from Google’s 36.9%, and miles ahead of the 15.7% of MSN Search. By May 2012, Yahoo was down to just 13.4 percent and had shrunk for the previous nine consecutive months, and was being beaten even by the newly-released Bing. That same year, Yahoo had the largest layoffs in its corporate history, shedding nearly 2,000 employees — or 14% of its overall workforce. [He] was so shit at his job that in 2009 Yahoo effectively threw in the towel on its own search technology, instead choosing to license Bing’s engine in a ten-year deal.
Artificial intelligence can predict political beliefs from expressionless faces
I “deathbots” are helping people in China grieve — Avatars of deceased relatives are increasingly popular for consoling those in mourning, or hiding the deaths of loved ones from children.
MetaAI’s strange loophole. I can get a picture of macauley culk in home alone, but not macauley culkin — it starts creating the image as you type and stops when you get the full name.
Psychedelia was the first ever interactive ‘light synthesizer’. It was written for the Commodore 64 by Jeff Minter and published by Llamasoft in 1984. psychedelia syndrome is a book-length exploration of the assembly code behind the game and an atlas of the pixels and effects it generated.
Thermonator, the first-ever flamethrower-wielding robot dog, $9,420

Hackaday: Chinese Subs May Be Propelled Silently By Lasers

If sharks with lasers on their heads weren’t bad enough, now China is working on submarines with lasers on their butts. At least, that’s what this report in the South China Morning Post claims, anyway.
According to the report, two-megawatt lasers are directed through fiber-optic cables on the surface of the submarine, vaporizing seawater and creating super-cavitation bubbles, which reduce drag on the submarine. The report describes it as an “underwater fiber laser-induced plasma detonation wave propulsion” system and claims that the system could generate up to 70,000 newtons of thrust, more than one of the turbofan engines on a 747.
The report (this proxy can get around the paywall) claims that the key to the system are the tiny metal spheres that direct the force of the cavitation implosion to propel the submarine. Similar to a magnetohydrodynamic drive (MHD), there’s no moving parts to make noise. Such a technology has the potential to make China’s submarines far harder to detect.
Looking for more details, we traced the report back to the original paper written by several people at Harbin Engineering University, entitled “Study on nanosecond pulse laser propulsion microspheres based on a tapered optical fiber in water environment“, but it’s still a pre-print. If you can get access to the full paper, feel free to chime in — we’d love to know if this seems like a real prospect or just exaggerated reporting by the local propaganda media.
[Image via Wikimedia Commons]
MetaFilter: Life After Running
It is not a replacement for running, but to live with a chronic condition is to become an expert at negotiating between one's wants and one's capacities. It means constantly hacking away at the richness of one's life—there is nothing casual about it.
Recent additions: call-alloy 0.5.0.1
A simple library to call Alloy given a specification
Slashdot: Flame-Throwing Robot Dog Now Available Under $10,000
Read more of this story at Slashdot.
Recent additions: haskoin-store 1.5.2
Storage and index for Bitcoin and Bitcoin Cash
Recent additions: call-alloy 0.5
A simple library to call Alloy given a specification
Open Culture: Steven Spielberg Calls Stanley Kubrick’s A Clockwork Orange “the First Punk Rock Movie Ever Made”

Steven Spielberg and Stanley Kubrick are two of the first directors whose names young cinephiles get to know. They’re also names between which quite a few of those young cinephiles draw a battle line: you may have enjoyed films by both of these auteurs, but ultimately, you’re going to have to side with one cinematic ethos or the other. Yet Spielberg clearly admires Kubrick himself: his 2001 film A.I. Artificial Intelligence originated as an unfinished Kubrick project, and he’s gone on record many times praising Kubrick’s work.
This is true even of such an un-Spielbergian picture as A Clockwork Orange, a collection of Spielberg’s comments on which you can hear collected in the video above. He calls it “the first punk-rock movie ever made. It was a very bleak vision of a dangerous future where young people, teenagers, are free to roam the streets without any kind of parental exception. They break into homes, and they assault and rape people. The subject matter was dangerous.” On one level, you can see how this would appeal to Spielberg, who in his own oeuvre has returned over and over again to the subject of youth.
Yet Kubrick makes moves that seem practically inconceivable to Spielberg, “especially the scene where you hear Gene Kelly singing ‘Singin’ in the Rain’ ” when Malcolm McDowell’s Alex DeLarge is “kicking a man practically to death. That was one of the most horrifying things I think I’ve ever witnessed.” And indeed, such a savage counterpoint between music and action is nowhere to be found in the filmography of Steven Spielberg, which has received criticism from the Kubrick-enjoyers of the world for the emotional one-dimensionality of its scores (even those composed by his acclaimed longtime collaborator John Williams).
Less fairly, Spielberg has also been charged with an inability to resist happy endings, or at least a discomfort with ambiguous ones. He would never, in any case, end a picture the way he sees Kubrick as having ended A Clockwork Orange: despite the intensive “deprogramming” Alex undergoes, “he comes out the other end more charming, more witty, and with such a devilish wink and blink at the audience, that I am completely certain that when he gets out of that hospital, he’s going to kill his mother and his father and his partners and his friends, and he’s going to be worse than he was when he went in.” To Spielberg’s mind, Kubrick made a “defeatist” film; yet he, like every Kubrick fan, must also recognize it as an artistic victory.
Related content:
Steven Spielberg on the Genius of Stanley Kubrick
Based in Seoul, Colin Marshall writes and broadcasts on cities, language, and culture. His projects include the Substack newsletter Books on Cities, the book The Stateless City: a Walk through 21st-Century Los Angeles and the video series The City in Cinema. Follow him on Twitter at @colinmarshall or on Facebook.
Hackaday: Flute Now Included on List of Human Interface Devices
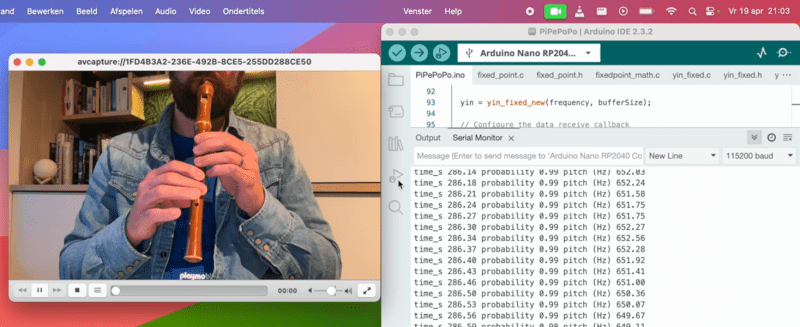
For decades now, we’ve been able to quickly and reliably interface musical instruments to computers. These tools have generally made making and recording music much easier, but they’ve also opened up a number of other out-of-the-box ideas we might not otherwise see or even think about. For example, [Joren] recently built a human interface device that lets him control a computer’s cursor using a flute instead of the traditional mouse.
Rather than using a MIDI interface, [Joren] is using an RP2040 chip to listen to the flute, process the audio, and interpret that audio before finally sending relevant commands to control the computer’s mouse pointer. The chip is capable of acting as a mouse on its own, but it did have a problem performing floating point calculations to the audio. This was solved by converting these calculations into much faster fixed point calculations instead. With a processing improvement of around five orders of magnitude, this change allows the small microcontroller to perform all of the audio processing.
[Joren] also built a Chrome browser extension that lets a flute player move a virtual cursor of sorts (not the computer’s actual cursor) from within the browser, allowing those without physical hardware to try out their flute-to-mouse skills. If you prefer your human interface device to be larger, louder, and more trombone-shaped we also have a trombone-based HID for those who play the game Trombone Champ.
MetaFilter: "I will not speak with her."
Penny Arcade: Lisan al Gabe
Slashdot: US Breaks Ground On Its First-Ever High-Speed Rail
Read more of this story at Slashdot.
Recent additions: bech32-th 1.1.6
Template Haskell extensions to the Bech32 library.
Recent additions: bech32 1.1.6
Implementation of the Bech32 cryptocurrency address format (BIP 0173).
MetaFilter: Listening at Two Very Different Scales
Hackaday: No Active Components in This Mysterious Audio Oscillator

What’s the simplest audio frequency oscillator you can imagine? There’s the 555, of course, and we can think of a few designs using just two transistors or even a few with just one. But how about an oscillator with no active components? Now there’s a neat trick.
Replicating [Stelian]’s “simplest audio oscillator on the Internet” might take some doing on your part, since it relies on finding an old telephone. Like, really old — you’ll need one with the carbon granule cartridge in the handset, along with the speaker. Other than that, all you’ll need is a couple of 1.5-volt batteries, wiring everything in one big series loop, and placing the microphone and speaker right on top of each other. Apply power and you’re off to the races. [Stelian]’s specific setup yielded a 2.4-kHz tone that could be altered a bit by repositioning the speaker relative to the mic. On the oscilloscope, the waveform is a pretty heavily distorted sine wave.
It’s a bit of a mystery to [Stelian] as to how this works without something to provide at least a little gain. Perhaps the enclosure of the speaker or the mic has a paraboloid shape that amplifies the sound just enough to kick things off? Bah, who knows? Let the hand-waving begin!
MetaFilter: The six directions: North, South, East, West, Anth and Kenth
The spoiler (in rot13): Ng gur raq bs 4Q tbys vf n svir qvzrafvbany tbys zbqr. CodeParade discusses how he implemented it here. (11 minutes, link is spoilerly)
MetaFilter: Outback cattle property to expand national park
Slashdot: US Bans Noncompete Agreements For Nearly All Jobs
Read more of this story at Slashdot.
Disquiet: Es Devlin’s Model Forest

A highlight from the Es Devlin exhibit at the Cooper Hewitt Museum in Manhattan. This is a plan for her installation at the 2021 Art Basel in Miami Beach, Florida. Titled Five Echoes, it was a full-scale maze based on the floor of the Chartres Cathedral, a “sound sculpture” that contained a “temporary forest”: “We immersed visitors within a soundscape that Invited them to learn each plant and tree species’ name, making a habitat for the non-human species within the human imagination.” The exhibit runs through August 11.
Slashdot: Generative AI Arrives In the Gene Editing World of CRISPR
Read more of this story at Slashdot.
Schneier on Security: Dan Solove on Privacy Regulation
Law professor Dan Solove has a new article on privacy regulation. In his email to me, he writes: “I’ve been pondering privacy consent for more than a decade, and I think I finally made a breakthrough with this article.” His mini-abstract:
In this Article I argue that most of the time, privacy consent is fictitious. Instead of futile efforts to try to turn privacy consent from fiction to fact, the better approach is to lean into the fictions. The law can’t stop privacy consent from being a fairy tale, but the law can ensure that the story ends well. I argue that privacy consent should confer less legitimacy and power and that it be backstopped by a set of duties on organizations that process personal data based on consent.
Full abstract:
Consent plays a profound role in nearly all privacy laws. As Professor Heidi Hurd aptly said, consent works “moral magic”—it transforms things that would be illegal and immoral into lawful and legitimate activities. As to privacy, consent authorizes and legitimizes a wide range of data collection and processing.
There are generally two approaches to consent in privacy law. In the United States, the notice-and-choice approach predominates; organizations post a notice of their privacy practices and people are deemed to consent if they continue to do business with the organization or fail to opt out. In the European Union, the General Data Protection Regulation (GDPR) uses the express consent approach, where people must voluntarily and affirmatively consent.
Both approaches fail. The evidence of actual consent is non-existent under the notice-and-choice approach. Individuals are often pressured or manipulated, undermining the validity of their consent. The express consent approach also suffers from these problems people are ill-equipped to decide about their privacy, and even experts cannot fully understand what algorithms will do with personal data. Express consent also is highly impractical; it inundates individuals with consent requests from thousands of organizations. Express consent cannot scale.
In this Article, I contend that most of the time, privacy consent is fictitious. Privacy law should take a new approach to consent that I call “murky consent.” Traditionally, consent has been binary—an on/off switch—but murky consent exists in the shadowy middle ground between full consent and no consent. Murky consent embraces the fact that consent in privacy is largely a set of fictions and is at best highly dubious.
Because it conceptualizes consent as mostly fictional, murky consent recognizes its lack of legitimacy. To return to Hurd’s analogy, murky consent is consent without magic. Rather than provide extensive legitimacy and power, murky consent should authorize only a very restricted and weak license to use data. Murky consent should be subject to extensive regulatory oversight with an ever-present risk that it could be deemed invalid. Murky consent should rest on shaky ground. Because the law pretends people are consenting, the law’s goal should be to ensure that what people are consenting to is good. Doing so promotes the integrity of the fictions of consent. I propose four duties to achieve this end: (1) duty to obtain consent appropriately; (2) duty to avoid thwarting reasonable expectations; (3) duty of loyalty; and (4) duty to avoid unreasonable risk. The law can’t make the tale of privacy consent less fictional, but with these duties, the law can ensure the story ends well.
Hackaday: New JEDEC DDR5 Memory Specification: Up To 8800 MT/s, Anti-Rowhammer Features

As DDR SDRAM increases in density and speed, so too do new challenges and opportunities appear. In the recent DDR5 update by JEDEC – as reported by Anandtech – we see not only a big speed increase from the previous maximum of 6800 Mbps to 8800 Mbps, but also the deprecation of Partial Array Self Refresh (PASR) due to security concerns, and the introduction of Per-Row Activation Counting (PRAC), which should help with row hammer-related (security) implications.
Increasing transfer speeds is primarily a matter of timings within the limits set by the overall design of DDR5, while the changes to features like PASR and PRAC are more fundamental. PASR is mostly a power-saving feature, but can apparently be abused for nefarious means, which is why it’s now gone. As for PRAC, this directly addresses the issue of row hammer attacks. Back in the 2014-era of DDR3, row hammer was mostly regarded as a way to corrupt data in RAM, but later it was found to be also a way to compromise security and effect exploits like privilege escalation.
The way PRAC seeks to prevent this is by keeping track of how often a row is being accessed, with a certain limit after which neighboring memory cells get a chance to recover from the bleed-over that is at the core of row hammer attacks. All of which means that theoretically new DDR5 RAM and memory controllers should be even faster and more secure, which is good news all around.
Slashdot: Try Something New To Stop the Days Whizzing Past, Researchers Suggest
Read more of this story at Slashdot.
Recent CPAN uploads - MetaCPAN: Call-Context-0.04
Sanity-check calling context
Changes for 0.04
- (no code changes)
- Switched to MIT license.
- Switched README from POD to Markdown.
- Removed Travis CI.
Recent CPAN uploads - MetaCPAN: App-sort_by_sortkey-0.001
Sort lines of text by a SortKey module
Changes for 0.001 - 2024-03-07
- First release.
Recent CPAN uploads - MetaCPAN: App-sort_by_comparer-0.002
Sort lines of text by a Comparer module
Changes for 0.002 - 2024-03-07
- No functional changes.
- [doc] Mention some related links.
Recent CPAN uploads - MetaCPAN: App-DateUtils-0.128
An assortment of date-/time-related CLI utilities
Changes for 0.128 - 2024-03-07
- [clis strftime, strftimeq] Use localtime() instead of gmtime(). We can still show UTC using "TZ=UTC strftime ...".
Planet Haskell: Well-Typed.Com: Improvements to the ghc-debug terminal interface
ghc-debug is a debugging tool for performing precise heap analysis of Haskell programs
(check out our previous post introducing it).
While working on Eras Profiling, we took the opportunity to make some much
needed improvements and quality of life fixes to both the ghc-debug library and the
ghc-debug-brick terminal user interface.
To summarise,
ghc-debugnow works seamlessly with profiled executables.- The
ghc-debug-brickUI has been redesigned around a composable, filter based workflow. - Cost centers and other profiling metadata can now be inspected using both the library interface and the TUI.
- More analysis modes have been integrated into the terminal interface such as the 2-level profile.
This post explores the changes and the new possibilities for inspecting
the heap of Haskell processes that they enable. These changes are available
by using the 0.6.0.0 version of ghc-debug-stub and ghc-debug-brick.
Recap: using ghc-debug
There are typically two processes involved when using ghc-debug on a live program.
The first is the debuggee process, which is the process whose heap you want to inspect.
The debuggee process is linked against the ghc-debug-stub package. The ghc-debug-stub
package provides a wrapper function
that you wrap around your main function to enable the use of ghc-debug. This wrapper
opens a unix socket and answers queries about the debuggee process’ heap, including
transmitting various metadata about the debuggee, like the ghc version it was compiled with,
and the actual bits that make up various objects on the heap.
The second is the debugger process, which queries the debuggee via the socket
mechanism and decodes the responses to reconstruct a view of the debuggee’s
Haskell heap. The most common debugger which people use is ghc-debug-brick, which
provides a TUI for interacting with the debuggee process.
It is an important principle of ghc-debug that the debugger and debuggee don’t
need to be compiled with the same version of GHC as each other. In other words,
a debugger compiled once is flexible to work with many different debuggees. With
our most recent changes debuggers now work seamlessly with profiled executables.
TUI improvements
Exploring Cost Center Stacks in the TUI
For debugging profiled executables, we added support for decoding
profiling information in the ghc-debug library. Once decoding support was added, it’s easy to display the
associated cost center stack information for each closure in the TUI, allowing you to
interactively explore that chain of cost
centers with source locations that lead to a particular closure being allocated.
This gives you the same information as calling the GHC.Stack.whoCreated function
on a closure, but for every closure on the heap!
Additionally, ghc-debug-brick allows you to search for closures that have been
allocated under a specific cost center.
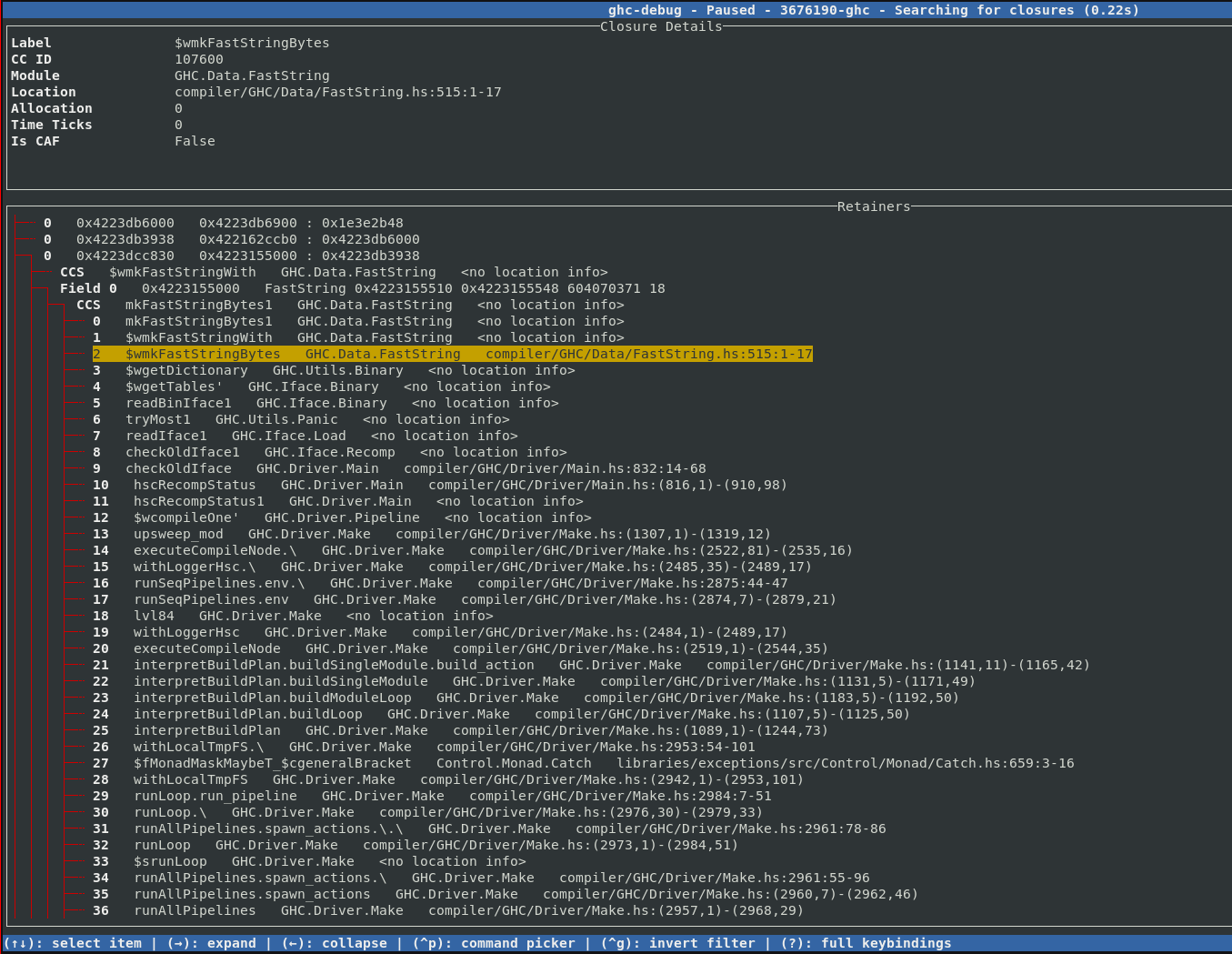
As we already discussed in the eras profiling blog post, object addresses are coloured according to the era they were allocated in.
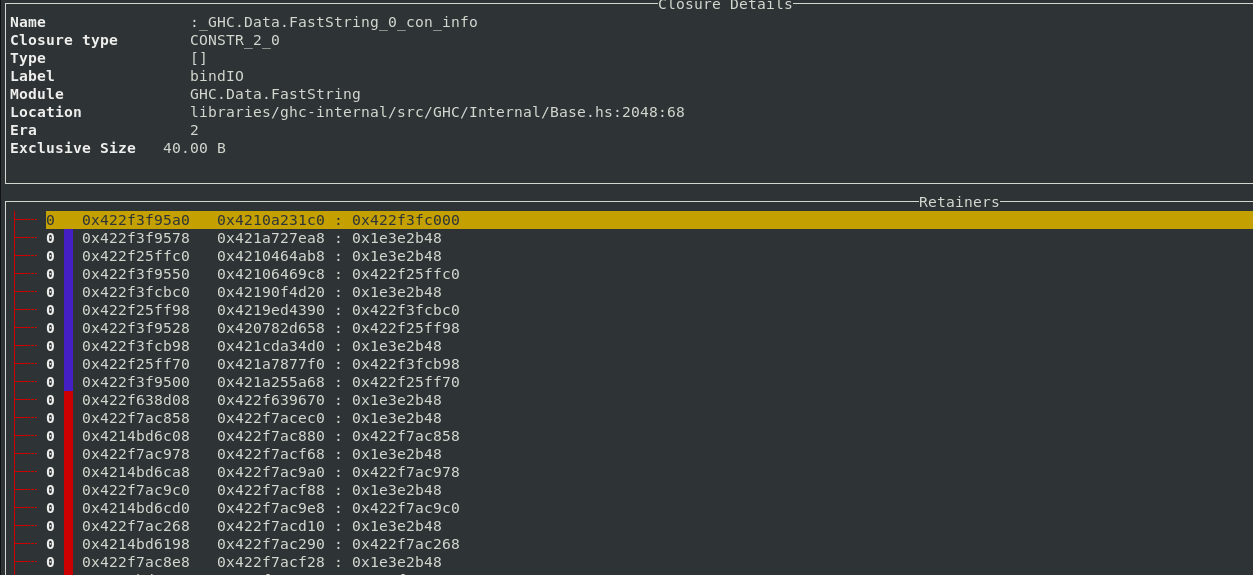
If other profiling modes like retainer profiling or biographical profiling are enabled, then the extra word tracked by those modes is used to mark used closures with a green line.
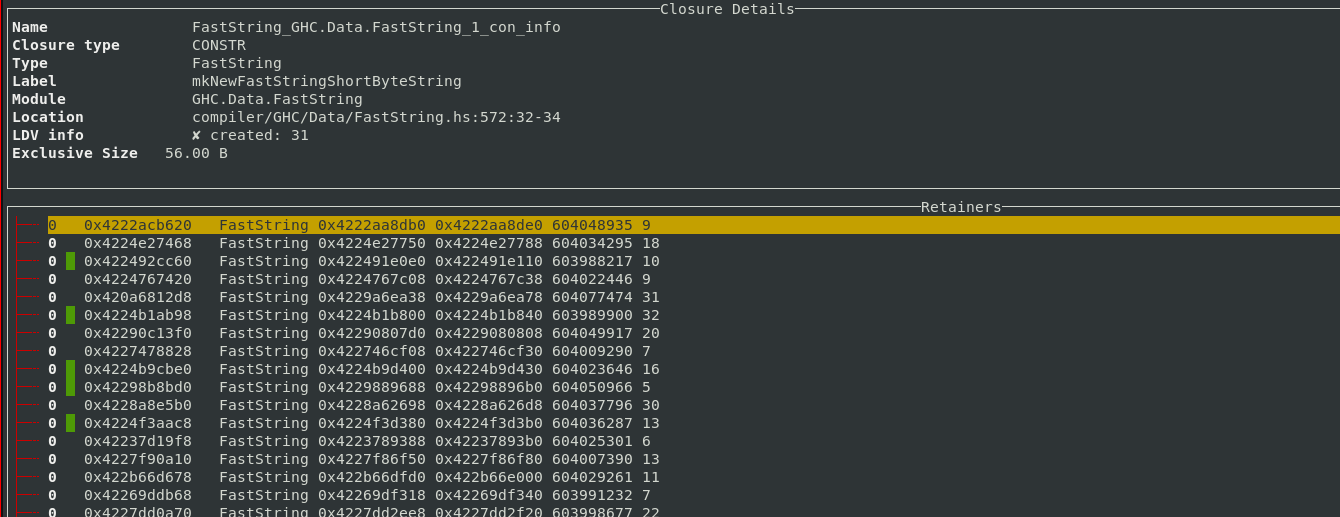
A filter based workflow
Typical ghc-debug-brick workflows would involve connecting to the client process
or a snapshot and then running queries like searches to track down the objects that
you are interested in. This took the form of various search commands available in the
UI:
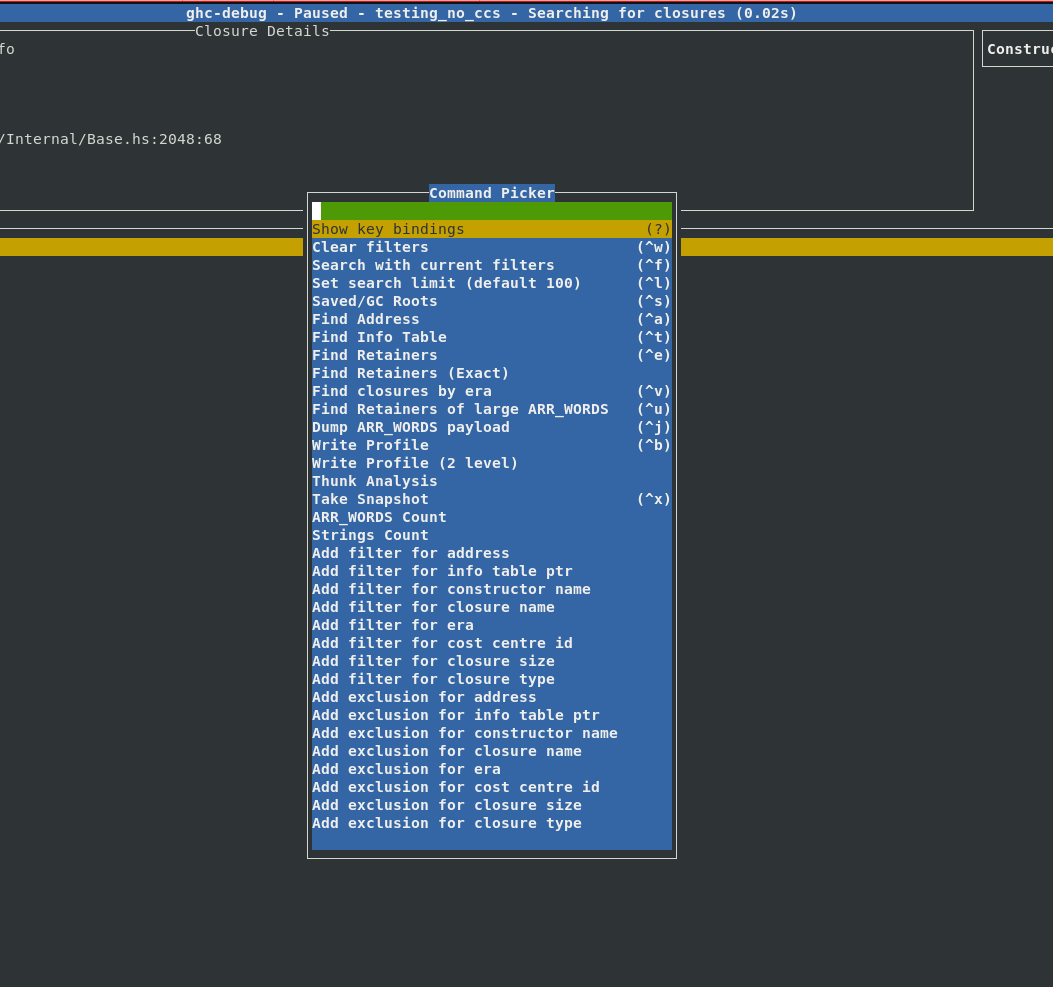
However, sometimes you would like to combine multiple search commands, in order to
more precisely narrow down the exact objects you are interested in. Earlier you
would have to do this by either writing custom queries with the ghc-debug Haskell
API or modify the ghc-debug-brick code itself to support your custom queries.
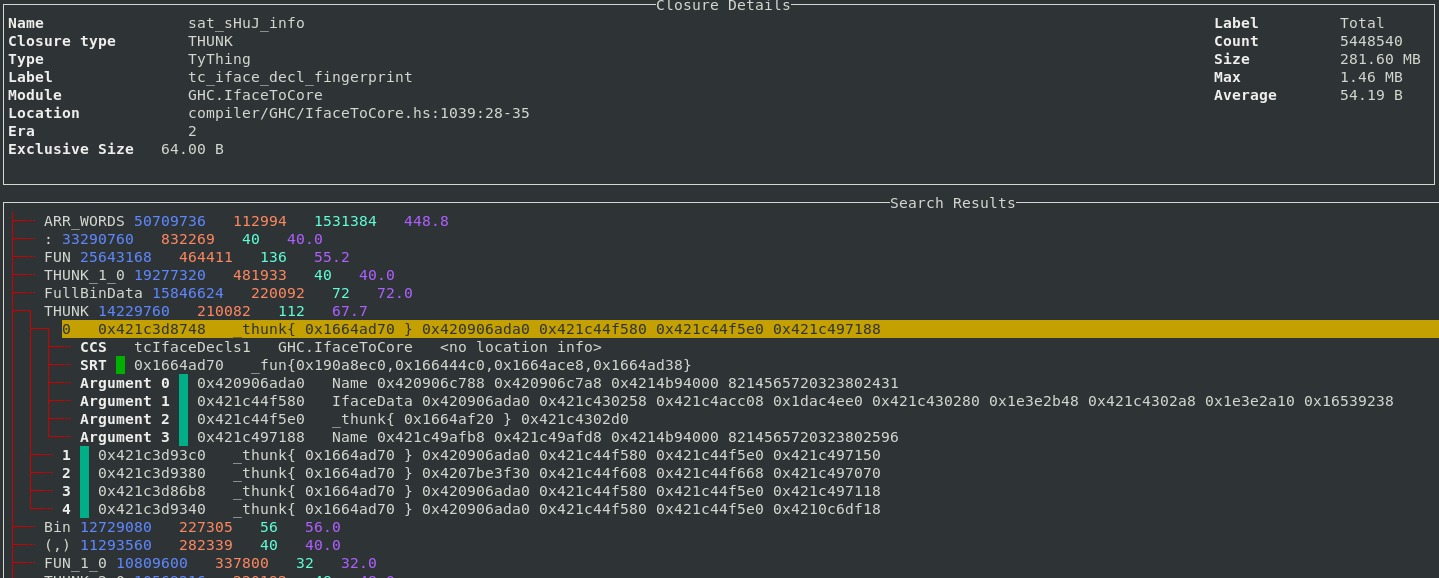
Filters provide a composable workflow in order to perform more advanced queries. You can select a filter to apply from a list of possible filters, like the constructor name, closure size, era etc. and add it to the current filter stack to make custom search queries. Each filter can also be inverted.
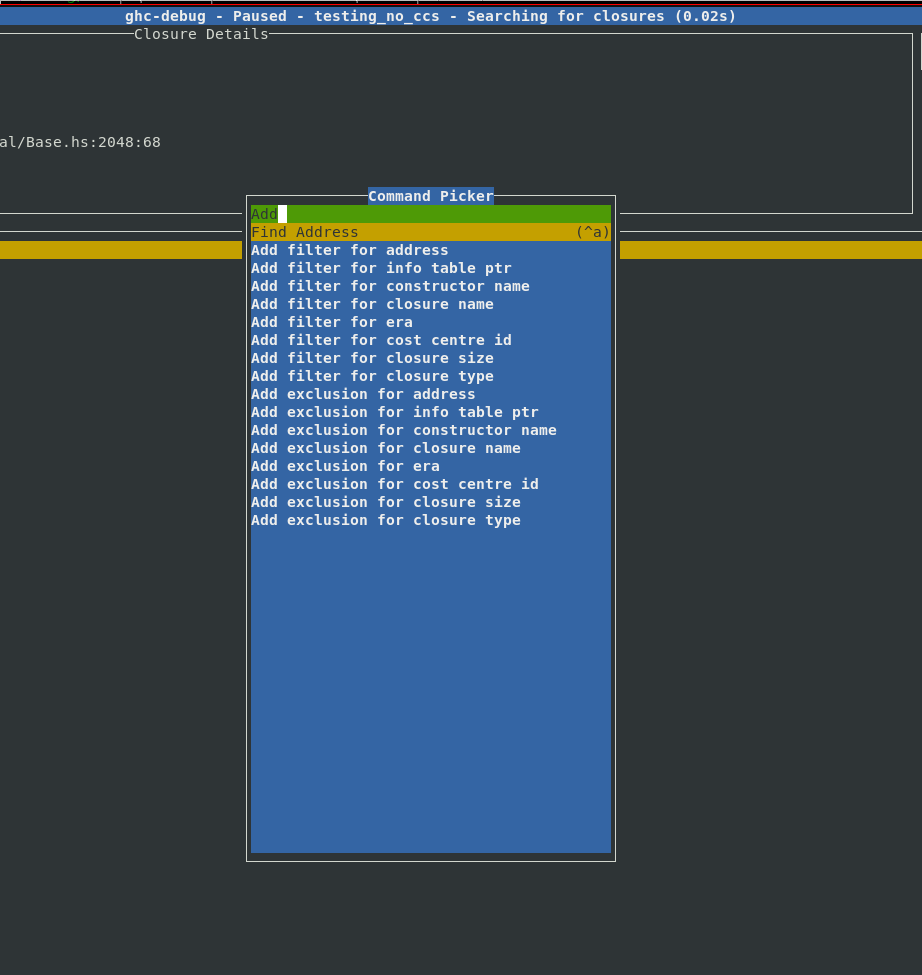
We were motivated to add this feature after implementing support for eras profiling as it was often useful to combine existing queries with a filter by era. With these filters it’s easy to express your own domain specific queries, for example:
- Find the
Fooconstructors which were allocated in a certain era. - Find all
ARR_WORDSclosures which are bigger than 1000 bytes. - Show me everything retained in this era, apart from
ARR_WORDSandGREconstructors.
Here is a complete list of filters which are currently available:
| Name | Input | Example | Action |
|---|---|---|---|
| Address | Closure Address | 0x421c3d93c0 | Find the closure with the specific address |
| Info Table | Info table address | 0x1664ad70 | Find all closures with the specific info table |
| Constructor Name | Constructor name | Bin | Find all closures with the given constructor name |
| Closure Name | Name of closure | sat_sHuJ_info | Find all closures with the specific closure name |
| Era | <era>/<start-era>-<end-era> | 13 or 9-12 | Find all closures allocated in the given era range |
| Cost centre ID | A cost centre ID | 107600 | Finds all closures allocated (directly or indirectly) under this cost centre ID |
| Closure Size | Int | 1000 | Find all closures larger than a certain size |
| Closure Type | A closure type description | ARR_WORDS | Find all ARR_WORDS closures |
All these queries are retainer queries which will not only show you the closures in question but also the retainer stack which explains why they are retained.
Improvements to profiling commands
ghc-debug-brick has long provided a profile command which performs a heap
traversal and provides a summary like a single sample from a -hT profile.
The result of this query is now displayed interactively in the terminal interface.
For each entry, the left column in the header shows the type of closure in
question, the total number of this closure type which are allocated,
the number of bytes on the heap taken up by this closure, the maximum size of each of
these closures and the average size of each allocated closure.
The right column shows the same statistics, but taken over all closures in the
current heap sample.
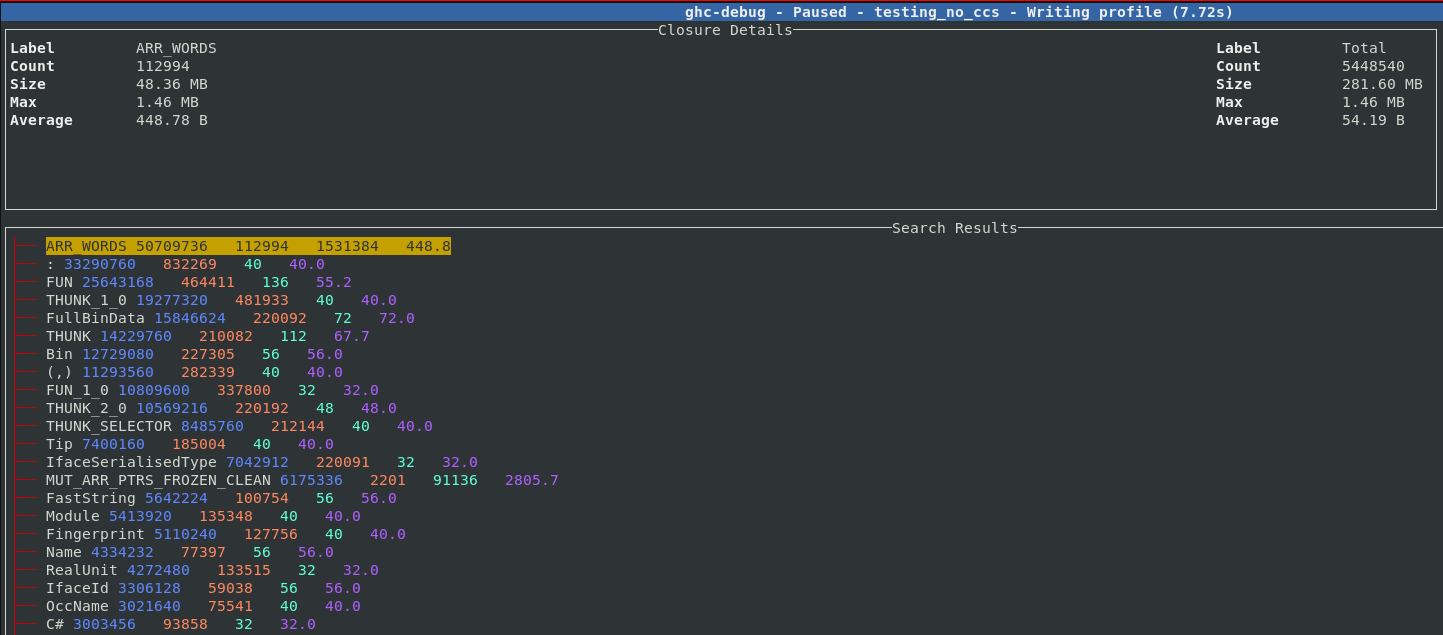
Each entry can be expanded, five sample points from each band are saved so you can inspect some closures which contributed to the size of the band. For example, here we expand the THUNK closure and can see a sample of 5 thunks which contribute to the 210,000 thunks which are live on this heap.
Support for the 2-level closure type profile has also been added to the TUI.
The 2-level profile is more fine-grained than the 1-level profile as the profile
key also contains the pointer arguments for the closure rather than just the
closure itself. The key :[(,), :] means the list cons constructor, where the head argument
is a 2-tuple, and the tail argument is another list cons.
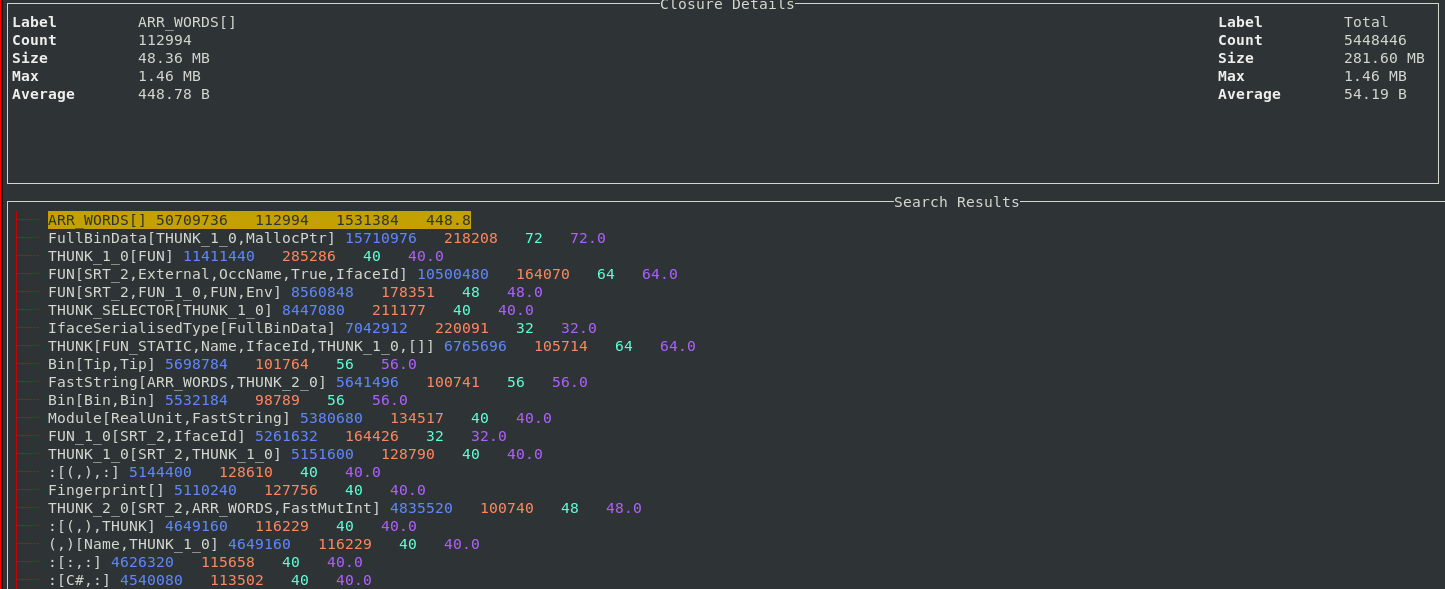
For example, in the 2-level profile, lists of different types will appear as different bands. In the profile above you can see 4 different bands resulting from lists, of 4 different types. Thunks also normally appear separately as they are also segmented based on their different arguments. The sample feature also works for the 2-level profile so it’s straightforward to understand what exactly each band corresponds to in your program.
Other UI improvements
In addition to the new features discussed above, some other recent enhancements include:
- Improved the performance of the main view when displaying a large number of rows. This noticeably reduces input lag while scrolling.
- The search limit was hard-coded to 100 objects, which meant that only the first few results of a search would be visible in the UI. This limit is now configurable in the UI.
- Additional analyses are now available in the TUI, such as finding duplicate
ARR_WORDSclosures, which is useful for identifying cases where programs end up storing many copies of the same bytestring.
Conclusion
We hope that the improvements to ghc-debug and ghc-debug-brick will aid the
workflows of anyone looking to perform detailed inspections of the heap of their
Haskell processes.
This work has been performed in collaboration with Mercury. Mercury have a long-term commitment to the scalability and robustness of the Haskell ecosystem and are supporting the development of memory profiling tools to aid with these goals.
Well-Typed are always interested in projects and looking for funding to improve GHC and other Haskell tools. Please contact info@well-typed.com if we might be able to work with you!
Recent CPAN uploads - MetaCPAN: Benchmark-DKbench-2.4_09
Hackaday: FLOSS Weekly Episode 780: Zoneminder — Better Call Randal

This week Jonathan Bennett and Aaron Newcomb chat with Isaac Connor about Zoneminder! That’s the project that’s working to store and deliver all the bits from security cameras — but the CCTV world has changed a lot since Zoneminder first started, over 20 years ago. The project is working hard to keep up, with machine learning object detection, WebRTC, and more. Isaac talks a bit about developer burnout, and a case or two over the years where an aggressive contributor seems suspicious in retrospect. And when is the next stable version of Zoneminder coming out, anyway?

Did you know you can watch the live recording of the show right in the Hackaday Discord? Have someone you’d like use to interview? Let us know, or contact the guest and have them contact us! Next week we’re taping the show on Tuesday, and looking for a guest!
Direct Download in DRM-free MP3.
If you’d rather read along, here’s the transcript for this week’s episode.
Colossal: Imagining Worlds After Climate Disaster, Julie Heffernan Melds Chaos and the Sublime

“Self Portrait as Emergency Shipwright” (2013), oil on canvas, 60 x 84 inches. All images © Julie Heffernan, shared with permission
Julie Heffernan likens her paintings to “advent calendars gone haywire.” Working in oil on canvas, the Brooklyn-based artist renders vast dreamworlds with tiny vignettes scattered across wider landscapes. Appearing from a distant or aerial perspective, the pieces envision the possibilities of life after fires, floods, and other climate disasters and potential opportunities for emerging anew.
Grand in scale and scope, the intricate paintings bear titles like “Self Portrait as Emergency Shipwright” and “Self Portrait with Sanctuary,” which nod to the personal details within each work. Various characters recur in the pieces, but where they once appeared alongside fresh fruit as an enduring metaphor for youthfulness, today, they’re surrounded by imagery of decay.”I find myself repeatedly drawn to landscape painting in order to explore my own issues, both planetary and personal,” she says. “I imagine landscapes that bear witness to our rise and fall as a great power but also to the workings of one woman’s mind.”

“Self-Portrait as Tree in Water” (2014), oil on canvas, 40 x 46 inches
Painting, the artist explains, is a way “to see better” and to place the struggles and difficulties of the world within a context. Despite fires raging in the background, or in the case of “Weather Change,” a massive iceberg rapidly melting in the seas, Heffernan’s works are not fatalistic, instead highlighting the immense beauty of human ingenuity. She adds in a statement:
I wanted imagery that might suggest other ways we could cope and possibly even flourish in a new extreme climate and to give my characters things they must tend. I give them water and tools to stop the burning; the tarred and feathered heads of big polluters; a library of great books to surround themselves with as they contend with the madness of man-made calamities.
Evoking the tradition of Hudson River School artists like Thomas Cole, Heffernan’s paintings focus on landscapes that appear amidst chaos as a sort of paradise. She’s also known to paint over and retouch works even after she’s deemed them complete, each time revising her idyllic vision and inching closer to the sublime.
It’s worth checking out an archive of the artist’s paintings to see how the scenes and characters have evolved. Follow her work on Instagram, along with updates about her graphic novel, Babe in the Woods: Or, the Art of Getting Lost, slated for release in September.

“Self-Portrait Between a Rock” (2014), oil on canvas, 68 x 66 inches

“Weather Change” (2019), oil on canvas, 74 x 96 inches

“Self Portrait with Sanctuary” (2017), oil on canvas, 102 x 76 inches

“Self-Portrait as Animal Bed” (2017), oil on canvas, 56 x 48 inches

“Study for SP with Mound” (2023), oil on canvas, 20 x 20 inches
Do stories and artists like this matter to you? Become a Colossal Member today and support independent arts publishing for as little as $5 per month. The article Imagining Worlds After Climate Disaster, Julie Heffernan Melds Chaos and the Sublime appeared first on Colossal.
ScreenAnarchy: THE BIG DOOR PRIZE S2 Review: Entering The Next Stage
 Chris O'Dowd, Gabrielle Dennis, Ally Maki, Damon Gupton, Josh Segarra, Crystal Fox, Sammy Fourlas and Djouliet Amara star in the Apple TV Plus series.
Chris O'Dowd, Gabrielle Dennis, Ally Maki, Damon Gupton, Josh Segarra, Crystal Fox, Sammy Fourlas and Djouliet Amara star in the Apple TV Plus series.
Colossal: In Ernesto Neto’s Largest Installation to Date, the World Is a Crocheted Ship Moving to a Single Rhythm

Photo by Joana Linda. All images © Ernesto Neto, courtesy of MAAT, shared with permission
An enormous, cascading installation of crocheted fabric strips stretches across a cavernous gallery in Ernesto Neto’s newest exhibition. At MAAT in Lisbon, the Brazilian artist (previously) presents Nosso Barco Tambor Terra, which translates to “our boat drum Earth,” a solo exhibition encompassing one of the largest suspended sculptures he has ever made.
Created with a team of assistants in his expansive Rio de Janeiro studio, the new piece draws on images of sails and maritime materials like canvas and rope. Neto nods to the history of transatlantic voyages between Europe and South America, stitching remnants of bright chintz, common in Brazil, into a swathe of fabric punctuated by points of interest like a vessel full of decorated drums or corn kernels, a symbol of international trade. Historically, the percussive instrument kept a rhythm for the galley rowers, some of whom would have been enslaved people.

Photo by Joana Linda
Suspended from the ceiling, the central work in Nosso Barco Tambor Terra adopts a cell-like structure, with numerous colors and patterns that intertwine, drape, stretch, and overlap. The piece suggests “a ship, a primordial beast, a forest, or even, and more likely, all of those things and infinite others,” writes curator Jacopo Crivelli Visconti in the exhibition text. He emphasizes that Neto portrays the world as a whole, defining the earth as “ancestral, pre-colonial, and even pre-human.”
The artist considers the dark legacies of enforced displacement and slavery during colonial rule, which the Portuguese implemented in Brazil. He situates the work as celebration of the planet’s array of people, cultures, and “worldviews whose strength and beauty one must recognise, reaffirm,” Visconti says. Amid destruction and chaos, Neto’s ark-like vessel envisions a way to propel the whole world forward.
The exhibition opens May 2 and continues through October 7 in Lisbon. Find more from MAAT.

Photo by Joana Linda

Photo by Joana Linda

Photos by Joana Linda

Photo by Joana Linda

Photo by Paulo Schettino

Photos by Joana Linda

Photo by Paulo Schettino
Do stories and artists like this matter to you? Become a Colossal Member today and support independent arts publishing for as little as $5 per month. The article In Ernesto Neto’s Largest Installation to Date, the World Is a Crocheted Ship Moving to a Single Rhythm appeared first on Colossal.
ScreenAnarchy: Fantaspoa 2024 Review: THE COMPLEX FORMS, How Classic Auteur Cinema Would Be If It Had More Monsters
 Strange things are happening at an ancient villa in the literal middle of nowhere. A bunch of men are gathered here, all of them with a peculiar contract. A middle-aged man named Christian (David White) is in the process of finalizing the deal with a mysterious, bossy looking man. Apparently, Christian is being paid a large sum of money for letting an unknown monster entity to possess his body for 12 days. He is not informed what this possession entails and when it will occur, only that he needn’t worry; the arrival of the creature will be announced by the sound of thunder. While waiting, Christian and the other man are busying themselves with household chores and speculating about what they really signed up for....
Strange things are happening at an ancient villa in the literal middle of nowhere. A bunch of men are gathered here, all of them with a peculiar contract. A middle-aged man named Christian (David White) is in the process of finalizing the deal with a mysterious, bossy looking man. Apparently, Christian is being paid a large sum of money for letting an unknown monster entity to possess his body for 12 days. He is not informed what this possession entails and when it will occur, only that he needn’t worry; the arrival of the creature will be announced by the sound of thunder. While waiting, Christian and the other man are busying themselves with household chores and speculating about what they really signed up for....
Tea Masters: Le thé est baroque comme la musique de Sven Schwannberger







 |
| Sven Schwannberger |




Saturday Morning Breakfast Cereal: Saturday Morning Breakfast Cereal - Picture

Click here to go see the bonus panel!
Hovertext:
Writing a book to convince a child they're special is like writing a book to convince a fish it can swim.
Today's News:
Greater Fool – Authored by Garth Turner – The Troubled Future of Real Estate: The Trump crash

In a Manhattan courtroom Donald Trump is currently on trial in a hush-money case the prosecution says amounts to election fraud and collusion.
The main players are sordid. A porn star. A man already convicted of fraud and sexual abuse facing three more criminal trials. His felon lawyer. The publisher of a sleazy supermarket tab.
What’s the best outcome for the economy, your house, mortgage, retirement and Canada?
That Trump be convicted, go to jail and never again set foot in the Oval Office.
This is the unmistakable conclusion of a new, detailed analysis by Jean-François Perrault, senior v-p and chief economist at Scotiabank, and his colleague Rene Lalonde. Released Tuesday, it details a dystopian aftermath of the coming US election between Joe Biden and his predecessor. Polls show it’s currently a toss-up between the two fossils. The bankers say a victory by either guy would be unfortunate. But a win by Trump would be a disaster. Especially for Canada.
With The Donald in power, and pursuing his agenda of tariffs, an assault on China, and mass deportations of US non-citizens, the outlook for the American economy would be dark. For us, it could trigger a widespread collapse, as forecast by the bank.
Canada would slump into a recession with a drop of 3.6% in national GDP. That compares with the 5% hit we took in 2020 because of the pandemic. But this time contraction would come with a major spike in inflation and explosion in interest rates – also when the federal government’s debt has doubled and service charges ballooned. In other words, the cupboard is bare this time. No CERB coming.
The bank says inflation, now 2.9%, would jump by 1.7% and the Bank of Canada would be forced to raise its policy rate, now 5%, by 1.9%. The prime at the chartered banks, currently 7.2%, would be 9.1%. HELOCs would jump past 10%, as would business and consumer loans. Mortgages would rise beyond 7% and the stress test move towards 10%.
In this scenario – recession, lower economic activity, swollen inflation, surging rates and higher unemployment – our real estate market would do well not to collapse. If a crumble did happen, the implications would be widespread including higher personal taxation to compensate for gutted public revenues over the four years of a Trump presidency. House prices might not drift lower, but instead plunge in such a scenario. The impact on the majority of Canadians with the bulk of their net worth in real estate could be profound.
Is this just Trump-bashing hate and panic coming from the woke towers on Bay Street?
Says the bank’s report:
“A Trump victory and follow-through on the policy side would likely see higher inflation than what could be expected in a Biden victory. Were Trump to implement the more controversial elements of his platform, namely the imposition of tariffs on all U.S. imports and the effective launch of a trade war, and the mass deportation of illegal immigrants, we would also expect substantial economic impacts in the United States and its trading partners. In that eventuality, large reductions in economic activity could be expected in the countries most dependent on U.S. trade (i.e., Canada and Mexico).”
Biden would raise taxes, the report clarifies, while Trump would cut them – especially for corporations. But the major economic impact would come from the launching of a trade tirade by 45. Says the bank: “Trump’s proposed 10% across-the-board increase in tariffs, with a special 60% carve-out for China, would effectively be the launch of a trade war, with damaging impacts on the United States and the rest of the world.” The US economy would shrink by more than 2%, inflation swell fast and the Fed would have to add 2% to rates. In response, the stock market would likely tank, and the 401k retirement funds of millions of equity-holding Americans be crushed.
“Given Canada’s greater reliance on trade,” adds Perrault, “the imposition of tariffs on all exports to the United States would lead to even greater economic harm north of the border.”
Look at this chart of the impact on Canada. There is little chance the current price of homes and condos, or the value of the TSX, your portfolio or the government’s ability to keep shovelling money out the door, would survive a Trump presidency intact.

And it’s not just trade policy. The guy is igniting public passion and support by calling illegal migrants ‘animals’ and promising the expulsion of millions of souls. “The deportation of roughly 10 million illegal immigrant implies a gradual fall of around 3% of the U.S. labour supply,” says Scotia. “U.S. employment and real GDP would gradually fall by 3% permanently…The shock is negative for U.S. stock markets…”
Finally, this analysis does not factor in Putin and Ukraine, Gaza and Israel, “the potential for civil disruption (regardless of who wins)”, China’s current real estate crisis nor a deterioration in American finances in the wake of the election. But you should.
This report can be read here.
If you’re not rooting for the prosecution, you’re not paying attention.
About the picture: “Hi, Garth! Here’s our 7 year old Cavi, Molly,” write Leslie and Sam. “She’s a serious Alpha girl. We certainly know who’s boss!”
To be in touch or send a picture of your beast, email to ‘garth@garth.ca’.
The Universe of Discourse: Well, I guess I believe everything now!
The principle of explosion is that in an inconsistent system
everything is provable: if you prove both and not-
for
any
,
you can then conclude
for any
:
$$(P \land \lnot P) \to Q.$$
This is, to put it briefly, not intuitive. But it is awfully hard to get rid of because it appears to follow immediately from two principles that are intuitive:
If we can prove that
is true, then we can prove that at least one of
is true. (In symbols,
.)
If we can prove that at least one of
.).
Then suppose that we have proved that is both true and false.
Since we have proved
true, we have proved that at least one of
or
is true. But because we have also proved that
is
false, we may conclude that
is true. Q.E.D.
This proof is as simple as can be. If you want to get rid of this, you have a hard road ahead of you. You have to follow Graham Priest into the wilderness of paraconsistent logic.
Raymond Smullyan observes that although logic is supposed to model ordinary reasoning, it really falls down here. Nobody, on discovering the fact that they hold contradictory beliefs, or even a false one, concludes that therefore they must believe everything. In fact, says Smullyan, almost everyone does hold contradictory beliefs. His argument goes like this:
Consider all the things I believe individually,
. I believe each of these, considered separately, is true.
However, I also believe that I'm not infallible, and that at least one of
is false, although I don't know which ones.
Therefore I believe both
(because I believe each of the
separately) and
(because I believe that not all the
And therefore, by the principle of explosion, I ought to believe that I believe absolutely everything.
Well anyway, none of that was exactly what I planned to write about. I was pleased because I noticed a very simple, specific example of something I believed that was clearly inconsistent. Today I learned that K2, the second-highest mountain in the world, is in Asia, near the border of Pakistan and westernmost China. I was surprised by this, because I had thought that K2 was in Kenya somewhere.
But I also knew that the highest mountain in Africa was Kilimanjaro. So my simultaneous beliefs were flatly contradictory:
- K2 is the second-highest mountain in the world.
- Kilimanjaro is not the highest mountain in the world, but it is the highest mountain in Africa
- K2 is in Africa
Well, I guess until this morning I must have believed everything!
Planet Haskell: Mark Jason Dominus: Well, I guess I believe everything now!
The principle of explosion is that in an inconsistent system
everything is provable: if you prove both and not-
for
any
,
you can then conclude
for any
:
$$(P \land \lnot P) \to Q.$$
This is, to put it briefly, not intuitive. But it is awfully hard to get rid of because it appears to follow immediately from two principles that are intuitive:
If we can prove that
If we can prove that at least one of
Then suppose that we have proved that is both true and false.
Since we have proved
true, we have proved that at least one of
or
is true. But because we have also proved that
is
false, we may conclude that
is true. Q.E.D.
This proof is as simple as can be. If you want to get rid of this, you have a hard road ahead of you. You have to follow Graham Priest into the wilderness of paraconsistent logic.
Raymond Smullyan observes that although logic is supposed to model ordinary reasoning, it really falls down here. Nobody, on discovering the fact that they hold contradictory beliefs, or even a false one, concludes that therefore they must believe everything. In fact, says Smullyan, almost everyone does hold contradictory beliefs. His argument goes like this:
Consider all the things I believe individually,
However, I also believe that I'm not infallible, and that at least one of
Therefore I believe both
And therefore, by the principle of explosion, I ought to believe that I believe absolutely everything.
Well anyway, none of that was exactly what I planned to write about. I was pleased because I noticed a very simple, specific example of something I believed that was clearly inconsistent. Today I learned that K2, the second-highest mountain in the world, is in Asia, near the border of Pakistan and westernmost China. I was surprised by this, because I had thought that K2 was in Kenya somewhere.
But I also knew that the highest mountain in Africa was Kilimanjaro. So my simultaneous beliefs were flatly contradictory:
- K2 is the second-highest mountain in the world.
- Kilimanjaro is not the highest mountain in the world, but it is the highest mountain in Africa
- K2 is in Africa
Well, I guess until this morning I must have believed everything!
Colossal: Max Naylor Rambles Through Mystical Woodlands in Ethereal Oil and Ink Paintings

“Storm Surge” (2023), ink on paper, 51 x 66 centimeters. All images © Max Naylor, shared with permission
Through ancient wooded glens and along rugged sea coasts, Max Naylor invites us to wander along shady passageways, squeeze between lichen-cloaked boulders, and inhale the fragrance of wildflowers. His detailed landscapes in ink and oil paint (previously) capture petals, branches, waves, and an array of botanicals in dreamlike scenes that teeter elegantly on the edge of reality.
Time of day is often indeterminate in Naylor’s paintings, where blue may suggest nighttime or just the shade cast below the cover of trees. Sometimes the scenes entice us into misty distances or a hilly horizon beyond. The artist employs atmospheric light and repeating tree trunks or flowers that verge on pure pattern, playing with our perception of presence and depth by drawing attention to all details at once.
If you’re in Bristol, stop by Spike Island Open Studios between May 3 and 5 to see Naylor’s work in person alongside more than 70 other artists. See more on the artist’s website and Instagram.

“Woodland Glade” (2024), ink on paper, 51 x 66 centimeters

“Erratic Boulder (after the deluge)” (2024), oil and ink on linen, 160 x 180 centimeters

“Early Glow” (2024), ink on paper, 51 x 66 centimeters

“Blue Landscape with Snowdrops” (2024), ink on paper, 51 x 66 centimeters

“Nestling” (2024), oil on linen, 75 x 95 centimeters

“Wild Wild Life” (2024), ink on paper, 51 x 66 centimeters

“Under the Gunnera” (2023), ink on paper, 51 x 66 centimeters

“Ragged Coast with Sea Cabbage” (2023), ink on paper, 51 x 66 centimeters
Do stories and artists like this matter to you? Become a Colossal Member today and support independent arts publishing for as little as $5 per month. The article Max Naylor Rambles Through Mystical Woodlands in Ethereal Oil and Ink Paintings appeared first on Colossal.
Ideas: Wilkie Collins: A true detective of the human mind
Considered one of the first writers of mysteries and the father of detective fiction, Wilkie Collins used the genres to investigate the rapidly changing world around him. UBC Journalism professor Kamal Al-Solaylee explores his work and its enduring power to make us look twice at the world we think we know.
OCaml Weekly News: OCaml Weekly News, 23 Apr 2024
- A second beta for OCaml 5.2.0
- An implementation of purely functional double-ended queues
- Feedback / Help Wanted: Upcoming OCaml.org Cookbook Feature
- Picos — Interoperable effects based concurrency
- Ppxlib dev meetings
- Ortac 0.2.0
- OUPS meetup april 2024
- Mirage 4.5.0 released
- patricia-tree 0.9.0 - library for patricia tree based maps and sets
- OCANNL 0.3.1: a from-scratch deep learning (i.e. dense tensor optimization) framework
- Other OCaml News
Open Culture: A Guided Tour of the Largest Handmade Model of Imperial Rome: Discover the 20x20 Meter Model Created During the 1930s

At the moment, you can’t see the largest, most detailed handmade model of Imperial Rome for yourself. That’s because the Museo della Civiltà Romana, the institution that houses it, has been closed for renovations since 2014. But you can get a guided tour of “Il Plastico,” as this grand Rome-in-miniature is known, through the new Ancient Rome Live video above. “The archaeologist and architect Italo Gismondi created this amazing model,” explains host Darius Arya, previously featured here on Open Culture for his tour of Pompeii. Working at a 1:250 scale, Gismondi built most of Il Plastico between 1933 and 1937, with later expansions after its installation in the Museo della Civiltà Romana.
Archaeologists and other scholars have, of course, learned more about the Eternal City over the past nine decades, knowledge reflected in regularly updated digital models like Rome Reborn. But none have showed Gismondi’s dedication to painstaking manual labor, which allowed him to craft practically every then-known architectural and infrastructural feature within the walls of Rome in the Constantinian age, from 306 to 337 AD.
Arya points out recognizable landmarks like the Colosseum, the Forum, and the Pyramid of Cestius as well as bridges, river fortifications, aqueducts, and even landscaping details down to the level of individual trees.
Even when the camera zooms way in, Gismondi’s Rome looks practically habitable (and indeed, it may appeal to some viewers more than do the modern European cities that are its descendants). It’s no wonder that Ridley Scott, a director famously sensitive to visual impact, would use the model in Gladiator. And while a video tour like Arya’s provides a closer-up view of many sections of Il Plastico than one can get in person, the only way to fully appreciate the sheer scale of the achievement is to behold its physical reality. Luckily, you should be able to do just that next year, when the Museo della Civiltà Romana is scheduled to reopen at long last. But then, no more could Rome be built in a day than its museum could be renovated in a mere decade.
Related content:
A Huge Scale Model Showing Ancient Rome at Its Architectural Peak (Built Between 1933 and 1937)
Rome Reborn: A New 3D Virtual Model Lets You Fly Over the Great Monuments of Ancient Rome
Interactive Map Lets You Take a Literary Journey Through the Historic Monuments of Rome
Ancient Rome’s System of Roads Visualized in the Style of Modern Subway Maps
Based in Seoul, Colin Marshall writes and broadcasts on cities, language, and culture. His projects include the Substack newsletter Books on Cities, the book The Stateless City: a Walk through 21st-Century Los Angeles and the video series The City in Cinema. Follow him on Twitter at @colinmarshall or on Facebook.
Open Culture: Watch Iconic Artists at Work: Rare Videos of Picasso, Matisse, Kandinsky, Renoir, Monet, Pollock & More
Claude Monet, 1915:

We’ve all seen their works in fixed form, enshrined in museums and printed in books. But there’s something special about watching a great artist at work. Over the years, we’ve posted film clips of some of the greatest artists of the 20th century caught in the act of creation. Today we’ve gathered together eight of our all-time favorites.
Above is the only known film footage of the French Impressionist Claude Monet, made when he was 74 years old, painting alongside a lily pond in his garden at Giverny. The footage was shot in the summer of 1915 by the French actor and dramatist Sacha Guitry for his patriotic World War I‑era film, Ceux de Chez Nous, or “Those of Our Land.” For more information, see our previous post, “Rare Film: Claude Monet at Work in His Famous Garden at Giverny, 1915.”
Pierre-Auguste Renoir, 1915:

You may never look at a painting by the French Impressionist Pierre-Auguste Renoir in quite the same way after seeing the footage above, which is also from Sacha Guitry’s Ceux de Chez Nous. Renoir suffered from severe rheumatoid arthritis during the last decades of his life. By the time this film was made in June of 1915, the 74-year-old Renoir was physically deformed and in constant pain. The painter’s 14-year-old son Claude is shown placing the brush in his father’s permanently clenched hand. To learn more about the footage and about Renoir’s terrible struggle with arthritis, be sure to read our post, “Astonishing Film of Arthritic Impressionist Painter, Pierre-Auguste Renoir (1915).”
Auguste Rodin, 1915:

The footage above, again by Sacha Guitry, shows the French sculptor Auguste Rodin in several locations, including his studio at the dilapidated Hôtel Biron in Paris, which later became the Musée Rodin. The film was made in late 1915, when Rodin was 74 years old. For more on Rodin and the Hôtel Biron, please see: “Rare Film of Sculptor Auguste Rodin working at his Studio in Paris (1915).”
Wassily Kandinsky, 1926:

In 1926, filmmaker Hans Cürlis took the rare footage above of the Russian abstract painter Wassily Kandinsky applying paint to a blank canvas at the Galerie Neumann-Nierendorf in Berlin. Kandinsky was about 49 years old at the time, and teaching at the Bauhaus. To learn more about Kandinsky and to watch a video of actress Helen Mirren discussing his work at the Museum of Modern Art in New York, see our post, “The Inner Object: Seeing Kandinsky.”
Henri Matisse, 1946:

The French artist Henri Matisse is shown above when he was 76 years old, making a charcoal sketch of his grandson, Gerard, at his home and studio in Nice. The clip is from a 26-minute film made by François Campaux for the French Department of Cultural Relations. To read a translation of Matisse’s spoken words and to watch a clip of the artist working on one of his distinctive paper cut-outs, go to “Vintage Film: Watch Henri Matisse Sketch and Make His Famous Cut-Outs (1946).”
Pablo Picasso, 1950:

In the famous footage above, Spanish artist Pablo Picasso paints on glass at his studio in the village of Vallauris, on the French Riviera. It’s from the 1950 film Visite à Picasso (A Visit with Picasso) by Belgian filmmaker Paul Haesaerts. Picasso was about 68 years old at the time. You can find the full 19-minute film here.
Jackson Pollock, 1951:

In the short film above, called Jackson Pollock 51, the American abstract painter talks about his work and creates one of his distinctive drip paintings before our eyes. The film was made by Hans Namuth when Pollock was 39 years old. To learn about Pollock and his fateful collaboration with Namuth, see “Jackson Pollock: Lights, Camera, Paint! (1951).”
Alberto Giacometti, 1965:

The Swiss artist Alberto Giacometti is most famous for his thin, elongated sculptures of the human form. But in the clip above from the 1966 film Alberto Giacometti by the Swiss photographer Ernst Scheidegger, Giacometti is shown working in another medium as he paints the foundational lines of a portrait at his studio in Paris. The footage was apparently shot in 1965, when Giacometti was about 64 years old and had less than a year to live. To learn about Giacometti’s approach to drawing and to read a translation of the German narration in this clip, be sure to see our post, “Watch as Alberto Giacometti Paints and Pursues the Elusive ‘Apparition,’ (1965).”
Related Content:
1922 Photo: Claude Monet Stands on the Japanese Footbridge He Painted Through the Years
The Universe of Discourse: R.I.P. Oddbins
I've just learned that Oddbins, a British chain of discount wine and liquor stores, went out of business last year. I was in an Oddbins exactly once, but I feel warmly toward them and I was sorry to hear of their passing.
In February of 2001 I went into the Oddbins on Canary Wharf and asked for bourbon. I wasn't sure whether they would even sell it. But they did, and the counter guy recommended I buy Woodford Reserve. I had not heard of Woodford before but I took his advice, and it immediately became my favorite bourbon. It still is.
I don't know why I was trying to buy bourbon in London. Possibly it was pure jingoism. If so, the Oddbins guy showed me up.
Thank you, Oddbins guy.
Planet Haskell: Mark Jason Dominus: R.I.P. Oddbins
I've just learned that Oddbins, a British chain of discount wine and liquor stores, went out of business last year. I was in an Oddbins exactly once, but I feel warmly toward them and I was sorry to hear of their passing.
In February of 2001 I went into the Oddbins on Canary Wharf and asked for bourbon. I wasn't sure whether they would even sell it. But they did, and the counter guy recommended I buy Woodford Reserve. I had not heard of Woodford before but I took his advice, and it immediately became my favorite bourbon. It still is.
I don't know why I was trying to buy bourbon in London. Possibly it was pure jingoism. If so, the Oddbins guy showed me up.
Thank you, Oddbins guy.
Disquiet: White Van, Whiteboard

This old white van is something of a neighborhood white board. It gets written over, and then it’s painted over, and then the circle of urban life begins anew.
Schneier on Security: Microsoft and Security Incentives
Former senior White House cyber policy director A. J. Grotto talks about the economic incentives for companies to improve their security—in particular, Microsoft:
Grotto told us Microsoft had to be “dragged kicking and screaming” to provide logging capabilities to the government by default, and given the fact the mega-corp banked around $20 billion in revenue from security services last year, the concession was minimal at best.
[…]
“The government needs to focus on encouraging and catalyzing competition,” Grotto said. He believes it also needs to publicly scrutinize Microsoft and make sure everyone knows when it messes up.
“At the end of the day, Microsoft, any company, is going to respond most directly to market incentives,” Grotto told us. “Unless this scrutiny generates changed behavior among its customers who might want to look elsewhere, then the incentives for Microsoft to change are not going to be as strong as they should be.”
Breaking up the tech monopolies is one of the best things we can do for cybersecurity.
Colossal: Hot Dogs, Rats, and Birkin Bags: Paa Joe’s Wooden Coffins Are an Ode to NYC’s Ubiquitous Sights

“Yellow Cab” (2024), Emele wood, enamel, cloth, acrylic, 92 x 27 x 44 inches. All images courtesy of Superhouse, shared with permission
New Yorkers are known for their unwavering devotion to the city, but would they want to spend eternity inside one of its once-ubiquitous taxis or worse yet, in the body of a wildly resilient subway rat?
In Celestial City at Superhouse, Ghanaian artist Paa Joe presents a sculptural ode to the Big Apple by carving an oversized rendition of the fruit, a Heinz ketchup bottle, a bagel with schmear, and more urban icons. Invoking the charms of all five boroughs, the painted wooden works open up to reveal the soft, padded insides of coffins, and two—the car and condiment—are even fit for humans.

Installation view of ‘Celestial City’
Since 1960, Paa Joe has been crafting caskets, which are known as abeduu adeka or proverb boxes to the Ga people, a community to which the artist belongs. Coffins are a crucial component to the safe passage of the dead to the afterlife and a family tradition for Paa Joe. A statement says:
In the early 1950s, Paa Joe’s uncle, Kane Kwei pioneered the first figurative coffin, a cocoa pod intended for a chief as a ceremonial palanquin. When the chief passed away during its construction, it was repurposed as his coffin. This innovative art form quickly gained popularity, and Kane Kwei began creating bespoke commissions resembling living and inanimate objects, symbolizing the deceased individual’s identity (an onion for a farmer, an eagle for a community leader, a sardine for a fisherman, etc.).
He continues this legacy today with his Fantasy Coffins series. In addition to the New York tributes, his works include a Campbell’s soup can, an Air Jordan sneaker, fish, and fruit. The sculptures often exaggerate scale, including the diminutive Statue of Liberty and a gigantic hot dog that shift perspectives on the quotidian.
Celestial City is on view through April 27. For a glimpse into Paa Joe’s carving process, visit Instagram.

Detail of “Sabrett” (2023), Emele wood, enamel, cloth, 23. 6 x 16. 5 x 11 inches

“Sabrett” (2023), Emele wood, enamel, cloth, 23. 6 x 16. 5 x 11 inches

Left: “Subway Rat” (2023), Emele wood, enamel, 24. 4 x 12. 6 x 11. 8 inches. Right: “Heinz” (2024), Emele wood, enamel , cloth, 26. 5 x 22. 5 x 94 inches

“Guggenheim” (2024), Emele wood, enamel, cloth, 29 x 22. 5 x 26. 5 inches

Detail of “Guggenheim” (2024), Emele wood, enamel, cloth, 29 x 22. 5 x 26. 5 inches

Detail of “Big Apple” (2024), Emele wood, enamel, artificial leaves, 19. 5 D x 26. 5 inches

Installation view of ‘Celestial City’
Do stories and artists like this matter to you? Become a Colossal Member today and support independent arts publishing for as little as $5 per month. The article Hot Dogs, Rats, and Birkin Bags: Paa Joe’s Wooden Coffins Are an Ode to NYC’s Ubiquitous Sights appeared first on Colossal.
Penny Arcade: Cyberyuck
We saw a Cybertruck in the wild when we were coming back from a funeral. It bore a kind of gentle symmetry, because Elon Musk will be buried beneath one figuratively and possibly literally because of how the gas pedal can slide off and get stuck under a manifold, locking the pedal into its highest level of push-downedness. It's fine, though - the thirty-eight hundred or so cybertrucks out in the wild are being brought in to have the footplate pop-riveted in, like they were shoeing a horse.
Saturday Morning Breakfast Cereal: Saturday Morning Breakfast Cereal - Immortal

Click here to go see the bonus panel!
Hovertext:
When you add in the Stalin potential it gets really dicey.
Today's News:
Saturday Morning Breakfast Cereal: Saturday Morning Breakfast Cereal - Good News

Click here to go see the bonus panel!
Hovertext:
The silver lining is due to cesium contamination.
Today's News:
new shelton wet/dry: ‘The old world is dying, and the new world struggles to be born: now is the time of monsters.’ –Antonio Gramsci

We do not have a veridical representation of our body in our mind. For instance, tactile distances of equal measure along the medial-lateral axis of our limbs are generally perceived as larger than those running along the proximal-distal axis. This anisotropy in tactile distances reflects distortions in body-shape representation, such that the body parts are perceived as wider than they are. While the origin of such anisotropy remains unknown, it has been suggested that visual experience could partially play a role in its manifestation.
To causally test the role of visual experience on body shape representation, we investigated tactile distance perception in sighted and early blind individuals […] Overestimation of distances in the medial-lateral over proximal-distal body axes were found in both sighted and blind people, but the magnitude of the anisotropy was significantly reduced in the forearms of blind people.
We conclude that tactile distance perception is mediated by similar mechanisms in both sighted and blind people, but that visual experience can modulate the tactile distance anisotropy.
new shelton wet/dry: from swerve of shore to bend of bay
Do you surf yourself?
No, I tried. I did it for about a week, 20 years ago. You have to dedicate yourself to these great things. And I don’t believe in being good at a lot of things—or even more than one. But I love to watch it. I think if I get a chance to be human again, I would do just that. You wake up in the morning and you paddle out. You make whatever little money you need to survive. That seems like the greatest life to me.
Or you could become very wealthy in early middle-age, stop doing the hard stuff, and go off and become a surfer.
No, no. You want to be broke. You want it to be all you’ve got. That’s when life is great. People are always trying to add more stuff to life. Reduce it to simpler, pure moments. That’s the golden way of living, I think.
related { Anecdote on Lowering the work ethic }
Greater Fool – Authored by Garth Turner – The Troubled Future of Real Estate: The 2-handle

To buy a house costing $2 million takes courage. And cash. Lots of it, including a 20% downpayment and a fat income. After putting $400,000 down and paying $73,000 in land transfer tax (in Toronto), the monthly mortgage nut is $10,300 (at 5.6%, five-year, 25-am). Plus property tax, insurance, utilities and upkeep. After shelling out $440,000 in interest over sixty months, you’d still owe $1.5 million.
By the way, this would require earnings of around $400,000 to qualify for financing. The average household income in T.O. is currently $110,000. Over 90% of people don’t make the cut.
So, how is this even possible? RBC already told us properties costing just over half this amount are severely unaffordable. The worst ever. Even when mortgages were 15% or more.
But wait. Look at what the house-humping Zoocasa site is claiming. The average house (not necessarily a nice one), it finds, will be at or above the $2 million mark by 2034. Ten years. So if you start today, kids, you only need to save $40,000 a year (and get a job as a bank CFO) to join in.
As rates fall, the Z people correctly point out, real estate rises in cost. “In the case that rates do begin declining this year, we can anticipate a corresponding price increase in the market overall, meaning we can reach this multimillion-dollar average home value even faster.”
Now, for the record, the sale price of a detached in 416 has touched $2 million briefly during a post-Covid Spring market. But it’s now retreated to the $1.7 million range. Of course, in many hoods $2 million continues to be merely the entry point. Rosedale is close to $4 million on average. Even the cheek-by-jowl mini McMansions of Leaside are routinely north of $2.5 million. The local real estate board stats show forty per cent of the entire city is in the two-mill zone. So, can prices actually migrate north everywhere?
Depends. If the economy stays positive and unemployment doesn’t spike (no recession) any interest rate declines will likely bring out more buyers willing to take the plunge. Meanwhile governments have been priming the pump. The latest dumb moves came from the feds, who have greenlit 30-year mortgages on new construction and bloated the RRSP homebuyer grab to $120,000 per couple.
Concurrently, Ottawa has seriously upped the capital gains inclusion rate on every investment asset save residential real estate. So, guess where more bucks will be flowing in the future? More dumbness.
Well, what’s the current thinking on rates?
Here are the expectations using the implied Canadian Dollar Offered Rate (CDOR) movements and probabilities based on BAX prices. In other words, what does Mr. Market think Tiff is gonna do?
The chances of a first cut of 25 basis points occurring in June sit at 74%. So, best plan on that happening. Further out, the betting is 50% that another quarter point will be shaved off in September, bringing the bank rate down to 4.5% and the bank prime to 6.7%.
By March of 2025 there’s currently an 86% chance the CB will slice another quarter point off, and a full-point drop (to 4%) will not occur until the autumn of next year (94% odds). So, clearly, rate expectations have been trimmed as the world steeps in volatility and, especially, as the US economy outperforms expectations.
This means the Fed will be higher for longer, while our CB lowers first to head off negative economic growth. As boss Jerome Powell said last week. “The recent data have clearly not given us greater confidence, and instead indicate that it’s likely to take longer than expected to achieve that confidence”. Just months ago the consensus of economists was for 125 bps of easing this year. That has now turned into just 40.
So, Mr. Market expects no change in June (83%), no change in July (57%), and maybe quarter-point drop in September (46%) and again in November (42%).
The American economy has surprised everyone, with 3% growth, full employment, rebounding profitability and over 20 new record stock market highs. Inflation is running hotter than in Canada and there’s consequently less pressure on the central bank. Complicating things is that weird presidential election – making Powell very cautious about any move that may be seen as political.
In short, it’s inevitable rates will drop. But not quite yet. Canada is also expected to see lower lending costs first. Combined with government desperation to encourage buyers, increase demand and push investment bucks from financials to real estate, the case for more house-buying remains strong.
And that sucks.
About the picture: “The “ferocious beast” picture in Thailand that you posted last week,” writes Alan, “prompted me to offer this picture taken outside a dog boutique (Feine pfote = Fine paws) in Linz, Austria while on our recent Rhine cruise (paid for out of our GT inspired b&d portfolio!) Thanks for the great daily reads.”
To be in touch or send a pisture of your beast, email to ‘garth@garth.ca’.
The Universe of Discourse: Talking Dog > Stochastic Parrot
I've recently needed to explain to nontechnical people, such as my chiropractor, why the recent ⸢AI⸣ hype is mostly hype and not actual intelligence. I think I've found the magic phrase that communicates the most understanding in the fewest words: talking dog.
These systems are like a talking dog. It's amazing that anyone could train a dog to talk, and even more amazing that it can talk so well. But you mustn't believe anything it says about chiropractics, because it's just a dog and it doesn't know anything about medicine, or anatomy, or anything else.
For example, the lawyers in Mata v. Avianca got in a lot of trouble when they took ChatGPT's legal analysis, including its citations to fictitious precendents, and submitted them to the court.
“Is Varghese a real case,” he typed, according to a copy of the exchange that he submitted to the judge.
“Yes,” the chatbot replied, offering a citation and adding that it “is a real case.”
Mr. Schwartz dug deeper.
“What is your source,” he wrote, according to the filing.
“I apologize for the confusion earlier,” ChatGPT responded, offering a legal citation.
“Are the other cases you provided fake,” Mr. Schwartz asked.
ChatGPT responded, “No, the other cases I provided are real and can be found in reputable legal databases.”
It might have saved this guy some suffering if someone had explained to him that he was talking to a dog.
The phrase “stochastic parrot” has been offered in the past. This is completely useless, not least because of the ostentatious word “stochastic”. I'm not averse to using obscure words, but as far as I can tell there's never any reason to prefer “stochastic” to “random”.
I do kinda wonder: is there a topic on which GPT can be trusted, a non-canine analog of butthole sniffing?
Addendum
I did not make up the talking dog idea myself; I got it from someone else. I don't remember who.
Planet Haskell: Mark Jason Dominus: Talking Dog > Stochastic Parrot
I've recently needed to explain to nontechnical people, such as my chiropractor, why the recent ⸢AI⸣ hype is mostly hype and not actual intelligence. I think I've found the magic phrase that communicates the most understanding in the fewest words: talking dog.
These systems are like a talking dog. It's amazing that anyone could train a dog to talk, and even more amazing that it can talk so well. But you mustn't believe anything it says about chiropractics, because it's just a dog and it doesn't know anything about medicine, or anatomy, or anything else.
For example, the lawyers in Mata v. Avianca got in a lot of trouble when they took ChatGPT's legal analysis, including its citations to fictitious precendents, and submitted them to the court.
“Is Varghese a real case,” he typed, according to a copy of the exchange that he submitted to the judge.
“Yes,” the chatbot replied, offering a citation and adding that it “is a real case.”
Mr. Schwartz dug deeper.
“What is your source,” he wrote, according to the filing.
“I apologize for the confusion earlier,” ChatGPT responded, offering a legal citation.
“Are the other cases you provided fake,” Mr. Schwartz asked.
ChatGPT responded, “No, the other cases I provided are real and can be found in reputable legal databases.”
It might have saved this guy some suffering if someone had explained to him that he was talking to a dog.
The phrase “stochastic parrot” has been offered in the past. This is completely useless, not least because of the ostentatious word “stochastic”. I'm not averse to using obscure words, but as far as I can tell there's never any reason to prefer “stochastic” to “random”.
I do kinda wonder: is there a topic on which GPT can be trusted, a non-canine analog of butthole sniffing?
Addendum
I did not make up the talking dog idea myself; I got it from someone else. I don't remember who.
Penny Arcade: Everything We Know about May/June Sticker Packs
I saw a Cybertruck in real life for the first time a few days ago. That is the ugliest vehicle I’ve ever seen and I can remember when people were buying the PT Cruiser. I can’t imagine a normal, human person seeing that monstrosity and thinking “That’s the truck for me!” What I’m saying is, Cybertruck owners don’t deserve rights.
Schneier on Security: Using Legitimate GitHub URLs for Malware
Interesting social-engineering attack vector:
McAfee released a report on a new LUA malware loader distributed through what appeared to be a legitimate Microsoft GitHub repository for the “C++ Library Manager for Windows, Linux, and MacOS,” known as vcpkg.
The attacker is exploiting a property of GitHub: comments to a particular repo can contain files, and those files will be associated with the project in the URL.
What this means is that someone can upload malware and “attach” it to a legitimate and trusted project.
As the file’s URL contains the name of the repository the comment was created in, and as almost every software company uses GitHub, this flaw can allow threat actors to develop extraordinarily crafty and trustworthy lures.
For example, a threat actor could upload a malware executable in NVIDIA’s driver installer repo that pretends to be a new driver fixing issues in a popular game. Or a threat actor could upload a file in a comment to the Google Chromium source code and pretend it’s a new test version of the web browser.
These URLs would also appear to belong to the company’s repositories, making them far more trustworthy.
ScreenAnarchy: Sound And Vision: Luca Guadagnino
 In the article series Sound and Vision we take a look at music videos from notable directors. This week we take a look at several music videos by Luca Guadagnino. Luca Guadagnino's films are vibrant and lush, pulsating with life and a heartbeat, like music. He is often one to curate his soundtracks carefully, with the likes of The Rolling Stones, Harry Nilsson, Captain Beefheart, Sufjan Stevens, Trent Reznor and Atticus Ross, Thom Yorke and John Adams showing up on his soundtracks. Sometimes he chooses pre-existing tracks, but more often he asks his favorite artists to provide the sonic backdrop for his films. It is fitting that a few of the music videos Guadagnino directed are for tracks tailor made for his own features, starting...
In the article series Sound and Vision we take a look at music videos from notable directors. This week we take a look at several music videos by Luca Guadagnino. Luca Guadagnino's films are vibrant and lush, pulsating with life and a heartbeat, like music. He is often one to curate his soundtracks carefully, with the likes of The Rolling Stones, Harry Nilsson, Captain Beefheart, Sufjan Stevens, Trent Reznor and Atticus Ross, Thom Yorke and John Adams showing up on his soundtracks. Sometimes he chooses pre-existing tracks, but more often he asks his favorite artists to provide the sonic backdrop for his films. It is fitting that a few of the music videos Guadagnino directed are for tracks tailor made for his own features, starting...
Colossal: Ewa Juszkiewicz’s Reimagined Historical Portraits of Women Scrutinize the Nature of Concealment

“Untitled (after Élisabeth Vigée Le Brun)” (2020), oil on canvas, 130 x 100 centimeters. All images © the artist, courtesy of Almine Rech, shared with permission
From elaborate hairstyles to hypertrophied mushrooms, an array of unexpected face coverings feature in Ewa Juszkiewicz’s portraits. Drawing on genteel likenesses of women primarily from the 18th and 19th centuries, the artist superimposes fabric, bouquets of fruit, foliage, and more, over the women’s faces.
In a collateral event during the 60th Annual Venice Biennale, presented by the Fundación Almine y Bernard Ruiz-Picasso and Almine Rech, Juszkiewicz presents a suite of works made between 2019 and 2024 that encapsulate her precise reconception of a popular Western genre. Locks with Leaves and Swelling Buds showcases her elaborate, technically accomplished pieces using traditional oil painting and varnishing techniques.
Juszkiewicz’s anonymous subjects are reminders of the systemic omission of women from the histories of art and the past more broadly. Literally in the face of portraits meant to memorialize and celebrate individuals, the artist erases their identities entirely, alluding only to the original artists’ names in the titles. In a seemingly contradictory approach, by drawing our attention to this erasure, Juszkiewicz stokes our curiosity about who they were.
“By covering the face of historical portraits, Juszkiewicz challenges the very essence of this genre: she destroys the portrait as such,” says curator Guillermo Solana. In a recent video, we get a peek inside the artist’s studio, where she describes how elements of another European painting tradition, the still life, proffers a rich well of symbolic objects to conceal each sitter’s face, from botanicals to ribbons to food.
Locks with Leaves and Swilling Buds continues in Venice at Palazzo Cavanis through September 1. Find more on the artist’s website and Instagram.

“Untitled (after François Gérard)” (2023), oil on canvas, 100 x 80 centimeters

“Untitled (after Joseph van Lerius)” (2020), oil on canvas, 70 x 55 centimeters

Left: “Portrait in Venetian Red (after Élisabeth-Louise Vigée Le Brun)” (2024), oil on canvas, 190 x 140 centimeters. Right: “Lady with a Pearl (after François Gérard)” (2024), oil on canvas, 80 x 65 centimeters

“Bird of paradise” (2023) oil on canvas, 200 x 160 centimeters. Photo by Serge Hasenböhler Fotografie
Do stories and artists like this matter to you? Become a Colossal Member today and support independent arts publishing for as little as $5 per month. The article Ewa Juszkiewicz’s Reimagined Historical Portraits of Women Scrutinize the Nature of Concealment appeared first on Colossal.








CreativeApplications.Net: Toaster-Typewriter – An investigation of humor in design

Toaster-Typewriter is the first iteration of what technology made with humor can do. A custom made machine that lets one burn letters onto bread, this hybrid appliance nudges users to exercise their imaginations while performing a mundane task like making toast in the morning.
Category: Objects
Tags: absurd / critique / device / eating / education / emotion / engineering / experience / experimental / machine / Objects / parsons / playful / politics / process / product design / reverse engineering / storytelling / student / technology / typewriter
People: Ritika Kedia
Michael Geist: The Law Bytes Podcast, Episode 200: Colin Bennett on the EU’s Surprising Adequacy Finding on Canadian Privacy Law

A little over five years ago, I launched the Law Bytes podcast with an episode featuring Elizabeth Denham, then the UK’s Information and Privacy Commissioner, who provided her perspective on Canadian privacy law. I must admit that I didn’t know what the future would hold for the podcast, but I certainly did not envision reaching 200 episodes. I think it’s been a fun, entertaining, and educational ride. I’m grateful to the incredible array of guests, to Gerardo Lebron Laboy, who has been there to help produce every episode, and to the listeners who regularly provide great feedback.
The podcast this week goes back to where it started with a look at Canadian privacy through the eyes of Europe. It flew under the radar screen for many, but earlier this year the EU concluded that Canada’s privacy law still provides an adequate level of protection for personal information. The decision comes as a bit of surprise to many given that Bill C-27 is currently at clause-by-clause review and there has been years of criticism that the law is outdated. To help understand the importance of the EU adequacy finding and its application to Canada, Colin Bennett, one of the world’s leading authorities on privacy and privacy governance, joins the podcast.
The podcast can be downloaded here, accessed on YouTube, and is embedded below. Subscribe to the podcast via Apple Podcast, Google Play, Spotify or the RSS feed. Updates on the podcast on Twitter at @Lawbytespod.
Show Notes:
Bennett, The “Adequacy” Test: Canada’s Privacy Protection Regime Passes, but the Exam Is Still On
EU Adequacy Finding, January 2024
Credits:
EU Reporter, EU Grants UK Data Adequacy for a Four Year Period
The post The Law Bytes Podcast, Episode 200: Colin Bennett on the EU’s Surprising Adequacy Finding on Canadian Privacy Law appeared first on Michael Geist.
Ideas: Salmon depletion in Yukon River puts First Nations community at risk
Once, there were half a million salmon in the Yukon River, but now they're almost gone. For the Little Salmon Carmacks River Nation, these salmon are an essential part of their culture — and now their livelihood is in peril. IDEAS shares their story as they struggle to keep their identity after the loss of the salmon migration.
Open Culture: Humans First Started Enjoying Cannabis in China Circa 2800 BC

Judging by how certain American cities smell these days, you’d think cannabis was invented last week. But that spike in enthusiasm, as well as in public indulgence, comes as only a recent chapter in that substance’s very long history. In fact, says the presenter of the PBS Eons video above, humanity began cultivating it “in what’s now China around 12,000 years ago. This makes cannabis one of the single oldest known plants we domesticate,” even earlier than “staples like wheat, corn, and potatoes.” By that time scale, it wasn’t so long ago — four millennia or so — that the lineages used for hemp and for drugs genetically separated from each other.
The oldest evidence of cannabis smoking as we know it, also explored in the Science magazine video below, dates back 2,500 years. “The first known smokers were possibly Zoroastrian mourners along the ancient Silk Road who burned pot during funeral rituals,” a proposition supported by the analysis of the remains of ancient braziers found at the Jirzankal cemetery, at the foot of the Pamir mountains in western China. “Tests revealed chemical compounds from cannabis, including the non-psychoactive cannabidiol, also known as CBD” — itself reinvented in our time as a thoroughly modern product — and traces of a THC byproduct called cannabinol “more intense than in other ancient samples.”
What made the Jirzankal cemetery’s stash pack such a punch? “The region’s high altitude could have stressed the cannabis, creating plants naturally high in THC,” writes Science’s Andrew Lawler. “But humans may also have intervened to breed a more wicked weed.” As cannabis-users of the sixties and seventies who return to the fold today find out, the weed has grown wicked indeed over the past few decades. But even millennia ago and half a world away, civilizations that had incorporated it for ritualistic use — or as a medical treatment — may already have been agriculturally guiding it toward greater potency. Your neighborhood dispensary may not be the most sublime place on Earth, but at least, when next you pay it a visit, you’ll have a sound historical reason to cast your mind to the Central Asian steppe.

Related content:
The Drugs Used by the Ancient Greeks and Romans
Algerian Cave Paintings Suggest Humans Did Magic Mushrooms 9,000 Years Ago
Pipes with Cannabis Traces Found in Shakespeare’s Garden, Suggesting the Bard Enjoyed a “Noted Weed”
Reefer Madness, 1936’s Most Unintentionally Hilarious “Anti-Drug” Exploitation Film, Free Online
Carl Sagan on the Virtues of Marijuana (1969)
Watch High Maintenance: A Critically-Acclaimed Web Series About Life & Cannabis
The New Normal: Spike Jonze Creates a Very Short Film About America’s Complex History with Cannabis
Based in Seoul, Colin Marshall writes and broadcasts on cities, language, and culture. His projects include the Substack newsletter Books on Cities, the book The Stateless City: a Walk through 21st-Century Los Angeles and the video series The City in Cinema. Follow him on Twitter at @colinmarshall or on Facebook.
Penny Arcade: Cyberyuck
TOPLAP: It’s a big week for live coding in France!
Last week it was /* VIU */ in Barcelona, this week it’s France!
Events
- Live Coding Study Day April 23, 2024
Organizers: Raphaël Forment, Agathe Herrou, Rémi Georges- 2 Academic sessions
- Speakers: Julian Rohrhuber, Yann Orlarey, and Stéphane Letz
- Evening concert, featuring performances selected by Artistic Director Rémi Georges balancing originality with a mix of local French and international artists. Lineup: Jia Liu (GER), Bruno Gola (Brazil/Berlin), Adel Faure (FR), ALFALFL (FR), Flopine (FR).
“While international networks centered on live-coding have been established for nearly 20 years through the TOPLAP collective, no academic event has ever taken place in France on this theme. The goal of this study day is to put in motion a national research network connected to its broader european and international counterparts.”
- Algorave in Lyon April 27 – 28 (12 hrs!) Live Streamed to YouTube.com/eulerroom
The 12 hour marathon Algorave is emerging as a unique French specialty (or maybe they just enjoy self-inflicted exhaustion…) Last year was a huge success so the team is back at it for more! 24 sound and/or visual artists including: th4, zOrg, Raphaël Bastide, Crash Server, Eloi el bon Noi, Adel Faure, Fronssons, QBRNTHSS, Bubobubobubo, azertype, eddy flux, + many more.
Rave on!
Disquiet: Pre-Show (Bill Frisell & Co.)
As I type this, I’m preparing to drive over to Berkeley, from San Francisco, to see guitarist Bill Frisell in a sextet that will be premiering new music. The group, who will play at Freight & Salvage, consists of Frisell plus violinist Jenny Scheinman, violist Eyvind Kang, cellist Hank Roberts, bassist Thomas Morgan, and drummer Rudy Royston.
There is, as far as I can tell, no available footage or audio of them playing as a group, so I’ve been piecing together a mental sonic image, as it were, from various smaller group settings.
These two short videos are all the strings from the sextet excepting the bass, filmed back on November 4, 2017. It’s the same group (Frisell, Sheinman, Kang, Roberts) who recorded the 2011 album Sign of Life (Savoy) and the 2005 album Richter 858 (Songlines). The latter was recorded back in 2002, so this is no new partnership by any means.
Roberts has, I believe, with Frisell, the longest-running association of all the musicians playing in the premiere. There’s plenty of examples, both commercial releases and live video, including this short piece, recorded June 15, 2014, at the New Directions Cello Festival, at Ithaca College, in Ithaca, New York.
Roberts was one of the first musicians I interviewed professionally, shortly after I got out of college in 1988. By then I had interviewed numerous musicians for a school publication, including the drummer Bill Bruford (Yes, King Crimson) and the Joseph Shabalala (founder of the vocal group Ladysmith Black Mambazo). After school I moved to New York City (first Manhattan and then Brooklyn), and for a solid swath of that time I was lucky to score a shared apartment on Crosby Street just south of Houston, incredibly close to the Knitting Factory, where I went several times a week and saw Frisell, Roberts, and so many “Downtown” musicians of that era in each other’s groups. I also saw Frisell play at the Village Vanguard around that time, but mostly just went to whatever was at the Knitting Factory on a given night. When I interviewed Roberts, it was on the subject of his then fairly new record, Black Pastels. (I wrote the piece for Pulse! magazine, published by Tower Records. In 1989 I moved to California to be an editor at Pulse!)
Frisell, bassist Morgan, and drummer Royston have recorded and toured widely and frequently in recent years. Here they are on July 3, 2023, at Arts Center at Duck Creek.
I’m imagining tonight’s music will have the “chamber Americana” quality of the quartet heard above, but the presence of Royston may rev things up a little, and it may have more of a jazz quality, closer to the trio work highlighted here.
The Shape of Code: Relative sizes of computer companies
How large are computer companies, compared to each other and to companies in other business areas?
Stock market valuation is a one measure of company size, another is a company’s total revenue (i.e., total amount of money brought in by a company’s operations). A company can have a huge revenue, but a low stock market valuation because it makes little profit (because it has to spend an almost equally huge amount to produce that income) and things are not expected to change.
The plot below shows the stock market valuation of IBM/Microsoft/Apple, over time, as a percentage of the valuation of tech companies on the US stock exchange (code+data on Github):
The growth of major tech companies, from the mid-1980s caused IBM’s dominant position to dramatically decline, while first Microsoft, and then Apple, grew to have more dominant market positions.
Is IBM’s decline in market valuation mirrored by a decline in its revenue?
The Fortune 500 was an annual list of the top 500 largest US companies, by total revenue (it’s now a global company list), and the lists from 1955 to 2012 are available via the Wayback Machine. Which of the 1,959 companies appearing in the top 500 lists should be classified as computer companies? Lacking a list of business classification codes for US companies, I asked Chat GPT-4 to classify these companies (responses, which include a summary of the business area). GPT-4 sometimes classified companies that were/are heavy users of computers, or suppliers of electronic components as a computer company. For instance, I consider Verizon Communications to be a communication company.
The plot below shows the ranking of those computer companies appearing within the top 100 of the Fortune 500, after removing companies not primarily in the computer business (code+data):
![]()
IBM is the uppermost blue line, ranking in the top-10 since the late-1960s. Microsoft and Apple are slowly working their way up from much lower ranks.
These contrasting plots illustrate the fact that while IBM continued to a large company by revenue, its low profitability (and major losses) and the perceived lack of a viable route to sustainable profitability resulted in it having a lower stock market valuation than computer companies with much lower revenues.
new shelton wet/dry: shadow trading
No evidence for differences in romantic love between young adult students and non-students — The findings suggest that studies investigating romantic love using student samples should not be considered ungeneralizable simply because of the fact that students constitute the sample.
Do insects have an inner life? Crows, chimps and elephants: these and many other birds and mammals behave in ways that suggest they might be conscious. And the list does not end with vertebrates. Researchers are expanding their investigations of consciousness to a wider range of animals, including octopuses and even bees and flies. […] Investigations of fruit flies (Drosophila melanogaster) show that they engage in both deep sleep and ‘active sleep’, in which their brain activity is the same as when they’re awake. “This is perhaps similar to what we call rapid eye movement sleep in humans, which is when we have our most vivid dreams, which we interpret as conscious experiences”
“This research shows the complexity of how caloric restriction affects telomere loss” After one year of caloric restriction, the participant’s actually lost their telomeres more rapidly than those on a standard diet. However, after two years, once the participants’ weight had stabilized, they began to lose their telomeres more slowly.
”It would mean that two-thirds of the universe has just disappeared”
AI study shows Raphael painting was not entirely the Master’s work
I bought 300 emoji domain names from Kazakhstan and built an email service [2021]
Shadow trading is a new type of insider trading that affects people who deal with material nonpublic information (MNPI). Insider trading involves investment decisions based on some kind of MNPI about your own company; shadow trading entails making trading decisions about other companies based on your knowledge of external MNPI. The issue has yet to be fully resolved in court, but the SEC is prosecuting this behavior. More: we provide evidence that shadow trading is an undocumented and widespread mechanism that insiders use to avoid regulatory scrutiny
The sessile lifestyle of acorn barnacles makes sexual reproduction difficult, as they cannot leave their shells to mate. To facilitate genetic transfer between isolated individuals, barnacles have extraordinarily long penises. Barnacles probably have the largest penis-to-body size ratio of the animal kingdom, up to eight times their body length
Daniel Lemire's blog: How do you recognize an expert?
Go back to the roots: experience. An expert is someone who has repeatedly solved the concrete problem you are encountering. If your toilet leaks, an experienced plumber is an expert. An expert has a track record and has had to face the consequences of their work. Failing is part of what makes an expert: any expert should have stories about how things went wrong.
I associate the word expert with ‘the problem’ because we know that expertise does not transfer well: a plumber does not necessarily make a good electrician. And within plumbing, there are problems that only some plumbers should solve. Furthermore, you cannot abstract a problem: you can study fluid mechanics all you want, but it won’t turn you into an expert plumber.
That’s one reason why employers ask for relevant experience: they seek expertise they can rely on. It is sometimes difficult to acquire expertise in an academic or bureaucratic setting because the problems are distant or abstract. Your experience may not translate well into practice. Sadly we live in a society where we often lose track of and undervalue genuine expertise… thus you may take software programming classes from people who never built software or civil engineering classes from people who never worked on infrastructure projects.
So… how do you become an expert? Work on real problems. Do not fall for reverse causation: if all experts dress in white, dressing in white won’t turn you into an expert. Listening to the expert is not going to turn you into an expert. Lectures and videos can be inspiring but they don’t build your expertise. Getting a job with a company that has real problems, or running your own business… that’s how you acquire experience and expertise.
Why would you want to when you can make a good living otherwise, without the hard work of solving real problems? Actual expertise is capital that can survive a market crash or a political crisis. After Germany’s defeat in 1945… many of the aerospace experts went to work for the American government. Relevant expertise is robust capital.
Why won’t everyone seek genuine expertise? Because there is a strong countervailing force: showing a total lack of practical skill is a status signal. Wearing a tie shows that you don’t need to work with your hands.
But again: don’t fall for reverse causality… broadcasting that you don’t have useful skills might be fun if you are already of high status… but if not, it may not grant you a higher status.
And status games without a solid foundation might lead to anxiety. If you can get stuff done, if you can fix problems, you don’t need to worry so much about what people say about you. You may not like the color of the shoes of your plumber, but you won’t snob him over it.
So get expertise and maintain it. You are likely to become more confident and happier.
Saturday Morning Breakfast Cereal: Saturday Morning Breakfast Cereal - The Test

Click here to go see the bonus panel!
Hovertext:
Look it's the only test with no false negatives.
Today's News:
Trivium: 21apr2024
Building a GPS Receiver using RTL-SDR, by Phillip Tennen.
Reproducing EGA typesetting with LaTeX, using the Baskervaldx font.
The Solution of the Zodiac Killer’s 340-Character Cipher, final, comprehensive report on the project by David Oranchak, Sam Blake, and Jarl Van Eycke.
Bridging brains: exploring neurosexism and gendered stereotypes in a mindsport, by Samantha Punch, Miriam Snellgrove, Elizabeth Graham, Charlotte McPherson, and Jessica Cleary.
Yotta is a minimalistic forth-like language bootstrapped from x86_64 machine code.
SSSL - Hackless SSL bypass for the Wii U, released one day after shutdown of the official Nintendo servers.
stagex, a container-native, full-source bootstrapped, and reproducible toolchain.
Computing Adler32 Checksums at 41 GB/s, by wooosh.
Random musings on the Agile Manifesto
doom-htop, “Ever wondered whether htop could be used to render the graphics of cult video games?”
A proper cup of tea, try this game!
Greater Fool – Authored by Garth Turner – The Troubled Future of Real Estate: The Sharia scare

“I’m Muslim,” Sam said. “So I can’t.”
We were building him a retirement portfolio a few years ago. Sam told me all about riba. Also why he couldn’t own any bonds, have a regular savings account or be talked into a GIC by TNL@TB.
He explained that Muslims who adhere to Islamic law have a different relationship with money. It’s not an asset all on its own, he told me. Instead money’s just a way of measuring things – like the value of work or the cost of a bungalow in Brantford. When you look at currency like that, it’s unethical (and wrong) to receive interest income from money alone. It’s called riba, and Islamic law forbids it.
So this is why Sam couldn’t own a bond paying interest semi-annually, or a GIC that dumped an earned amount into his lap each year. Or even a bank savings account earning a piddling little amount. He had one of those, he told me, but because riba cannot be used for personal benefit, he donated those dollars to the mosque.
We solved the portfolio thing easily. Bond ETFs don’t pay interest, but dividends which represent the earned amount and any capital gain. For tax purposes these are treated either as income or gains, and therefore comply with religious tenets.
But here was Sam’s real problem: getting a mortgage.
Home loans come with a big interest component – in fact, in the early years of amortization it’s the largest component of monthly payments. For a few years Muslim-friendly mortgages have been available from a few lenders, but they’ve been scarce and expensive, owing partly to the fact Muslims don’t believe in foreclosures, either. So the cost of a ‘halal’ loan (that means ’permitted’) has been about 4% more than non-believers pay for bank mortgages.
That brings us to Tuesday last. Ottawa’s federal budget is, “exploring new measures to expand access to halal mortgages” and other non-traditional borrowings.
Well, guess what happened next?
“Trudeau bringing Sharia law to Canada!” screamed the first of a slew of comments posted to this blog (all deleted). Soon social media was more of a dank, poisonous swamp than usual. The extreme elements of historical Sharia law (lashings, stonings, amputation for relatively minor crimes plus the subjugation of women) were bandied about as if soon to come to your hood. And people wondered why, if Muslims can get mortgages without interest being charged, the rest of us can’t?
As usual, there were two things in the background. Ignorance. And political manipulation.
I’m no expert on religious laws, the Quran or Islam, but the idea behind halal mortgages seems pretty simple. The buyer still pays the lender, just in a different way and just as much (or more). In one form, the lender buys the property with the purchaser in a rent-to-own situation. Or buyer and lender enter into a partnership with ownership being transferred as lump sum payments are made. In any case, there’s a profit component built in for the finance company that equals what a traditional amortized mortgage would yield. Presumably the feds are looking to allow more lenders to get into the game by figuring out appropriate forms of CMHC insurance, now that Muslim families form a growing (5% or 1.7 million) hunk of the population.
So, a halal mortgage ain’t cheaper. Nobody gets a free pony.
But what we all get is a new way for the haters to express prejudice. Just as the MAGA adherents to the south have vilified immigrants (especially the brown ones) and as ‘Christian nationalism’ is embraced by Donald Trump, society grows darker. Sadly, the rightist and populist movements there, here and in Europe attract followers by seeking to turn the clock back, recalling a former, whiter, more comfortable and familiar world. And so the man who may become the most powerful person in the world can call newcomers to his country ‘vermin’ and ‘animals’, suggesting they are ‘poisoning’ America and its school system.
Never in a lifetime did we think this could happen. But here we are.
For the record, Muslim-friendly home loans are a nothingburger. They don’t give borrowers an advantage. They level the playing field. They do not mean Sharia law is being imposed, enacted or considered. You are not being threatened.
Also for the record, how can thinking about money this way be a bad thing? Value what it does, not what it is.
About the picture: “Your favourite millennial here,” writes Liam. “My wife and I just adopted Lenny here from a breeder on Vancouver Island. He’s adjusting to life in Montreal well, but, like his main man, struggles with the language, the sporadic street cleaning and joykill landlords.”
To be in touch or send a picture of your beast, email to ‘garth@garth.ca’.
Planet Haskell: Oleg Grenrus: A note about coercions
Safe coercions in GHC are a very powerful feature. However, they are not perfect; and already many years ago I was also thinking about how we could make them more expressive.
In particular such things like "higher-order roles" have been buzzing. For the record, I don't think Proposal #233 is great; but because that proposal is almost four years old, I don't remember why; nor I have tangible counter-proposal either.
So I try to recover my thoughts.
I like to build small prototypes; and I wanted to build a small language with zero-cost coercions.
The first approach, I present here, doesn't work.
While it allows model coercions, and very powerful ones, these coercions are not zero-cost as we will see. For language like GHC Haskell where being zero-cost is non-negotiable requirement, this simple approach doesn't work.
The small "formalisation" is in Agda file https://gist.github.com/phadej/5cf29d6120cd27eb3330bc1eb8a5cfcc
Syntax
We start by defining syntax. Our language is "simple": there are types
A, B = A -> B -- function type, "arrow"coercions
co = refl A -- reflexive coercion
| sym co -- symmetric coercions
| arr co₁ co₂ -- coercion of arrows built from codomain and domain
-- type coercionsand terms
f, t, s = x -- variable
| f t -- application
| λ x . t -- lambda abstraction
| t ▹ co -- castObviously we'd add more stuff (in particular, I'm interested in expanding coercion syntax), but these are enough to illustrate the problem.
Because the language is simple (i.e. not dependent), we can define typing rules and small step semantics independently.
Typing
There is nothing particularly surprising in typing rules.
We'll need a "well-typed coercion" rules too though, but these are also very straigh-forward
Coercion Typing: Δ ⊢ co : A ≡ B
------------------
Δ ⊢ refl A : A ≡ A
Δ ⊢ co : A ≡ B
------------------
Δ ⊢ sym co : B ≡ A
Δ ⊢ co₁ : C ≡ A
Δ ⊢ co₂ : D ≡ B
-------------------------------------
Δ ⊢ arr co₁ co₂ : (C -> D) ≡ (A -> B)Terms typing rules are using two contexts, for term and coercion variables (GHC has them in one, but that is unhygienic, there's a GHC issue about that). The rules for variables, applications and lambda abstractions are as usual, the only new is the typing of the cast:
Term Typing: Γ; Δ ⊢ t : A
Γ; Δ ⊢ t : A
Δ ⊢ co : A ≡ B
-------------------------
Γ; Δ ⊢ t ▹ co : B So far everything is good.
But when playing with coercions, it's important to specify the reduction rules too. Ultimately it would be great to show that we could erase coercions either before or after reduction, and in either way we'll get the same result. So let's try to specify some reduction rules.
Reduction rules
Probably the simplest approach to reduction rules is to try to inherit most reduction rules from the system without coercions; and consider coercions and casts as another "type" and "elimination form".
An elimination of refl would compute trivially:
t ▹ refl A ~~> tThis is good.
But what to do when cast's coercion is headed by arr?
t ▹ arr co₁ co₂ ~~> ???One "easy" solution is to eta-expand t, and split the coercion:
t ▹ arr co₁ co₂ ~~> λ x . t (x ▹ sym co₁) ▹ co₂We cast an argument before applying it to the function, and then cast the result. This way the reduction is type preserving.
But this approach is not zero-cost.
We could not erase coercions completely, we'll still need some indicator that there were an arrow coercion, so we'll remember to eta-expand:
t ▹ ??? ~~> λ x . t xConclusion
Treating coercions as another type constructor with cast operation being its elimination form may be a good first idea, but is not good enough. We won't be able to completely erase such coercions.
Another idea is to complicate the system a bit. We could "delay" coercion elimination until the result is scrutinised by another elimination form, e.g. in application case:
(t ▹ arr co₁ co₂) s ~~> t (s ▹ sym co₁) ▹ co₂ And that is the approach taken in Safe Zero-cost Coercions for Haskell, you'll need to look into JFP version of the paper, as that one has appendices.
(We do not have space to elaborate, but a key example is the use ofnthin ruleS_KPUSH, presented in the extended version of this paper.)
The rule S_Push looks some what like:
---------------------------------------------- S_Push
(t ▹ co) s ~~> t (s ▹ sym (nth₁ co)) ▹ nth₂ cowhere we additionally have nth coercion constructor to decompose coercions.
Incidentally there was, technically is, a proposal to remove decomposition rule, but it's a wrong solution to the known problem. The problem and a proper solution was kind of already identified in the original paper
We could similarly imagine a lattice keyed by classes whose instance definitions are to be respected; with such a lattice, we could allow the coercion ofMap Int vtoMap Age vprecisely whenInt’s andAge’sOrdinstances correspond.
The original paper also identified the need for higher-order roles. And also identified that
This means that Monad instances could be defined only for types
that expect a representational parameter.
which I argue should be already required for Functor (and traverseBia hack with unlawful Mag would still work if GHC had unboxed representational coercions, i.e. GADTs with baked-in representational (not only nominal) coercions).
There also the mention of unidirectional Coercible, which people asked about later and recently:
Such uni-directional version of Coercible amounts to explicit
inclusive subtyping and is more complicated than our current symmetric system.
It is fascinating that authors were able to predict the relevant future work so well. And I'm thankful that GHC got Coercible implemented even it was already known to not be perfect. It's useful nevertheless. But I'm sad that there haven't been any results of future work since.
Embedded in Academia: Dataflow Analyses and Compiler Optimizations that Use Them, for Free
Compilers can be improved over time, but this is a slow process. “Proebsting’s Law” is an old joke which suggested that advances in compiler optimization will double the speed of a computation every 18 years — but if anything this is optimistic. Slow compiler evolution is never a good thing, but this is particularly problematic in today’s environment of rapid innovation in GPUs, TPUs, and other entertaining platforms.
One of my research group’s major goals is to create technologies that enable self-improving compilers. Taking humans out of the compiler-improvement loop will make this process orders of magnitude faster, and also the resulting compilers will tend to be correct by construction. One such technology is superoptimization, where we use an expensive search procedure to discover optimizations that are missing from a compiler. Another is generalization, which takes a specific optimization (perhaps, but not necessarily, discovered by a superoptimizer) and turns it into a broadly applicable form that is suitable for inclusion in a production compiler.
Together with a representative benchmark suite, superoptimization + generalization will result in a fully automated self-improvement loop for one part of an optimizing compiler: the peephole optimizer. In the rest of this piece I’ll sketch out an expanded version of this self-improvement loop that includes dataflow analyses.
The goal of a dataflow analysis is to compute useful facts that are true in every execution of the program being compiled. For example, if we can prove that x is always in the range [5..15], then we don’t need to emit an array bound check when x is used as an index into a 20-element array. This particular dataflow analysis is the integer range analysis and compilers such as GCC and LLVM perform it during every optimizing compile. Another analysis — one that LLVM leans on particularly heavily — is “known bits,” which tries to prove that individual bits of SSA values are zero or one in all executions.
Out in the literature we can find a huge number of dataflow analyses, some of which are useful to optimize some kinds of code — but it’s hard to know which ones to actually implement. We can try out different ones, but it’s a lot of work implementing even one new dataflow analysis in a production compiler. The effort can be divided into two major parts. First, implementing the analysis itself, which requires creating an abstract version of each instruction in the compiler’s IR: these are called dataflow transfer functions. For example, to implement the addition operation for integer ranges, we can use [lo1, hi1] + [lo2, hi2] = [lo1 + lo2, hi1 + hi2] as the transfer function. But even this particularly easy case will become tricker if we have to handle overflows, and then writing a correct and precise transfer function for bitwise operators is much less straightforward. Similarly, consider writing a correct and precise known bits transfer function for multiplication. This is not easy! Then, once we’ve finished this job, we’re left with the second piece of work which is to implement optimizations that take advantage of the new dataflow facts.
Can we automate both of these pieces of work? We can! There’s an initial bit of work in creating a representation for dataflow facts and formalizing their meaning that cannot be automated, but this is not difficult stuff. Then, to automatically create the dataflow transfer functions, we turn to this very nice paper which synthesizes them basically by squeezing the synthesized code between a hard soundness constraint and a soft precision constraint. Basically, every dataflow analysis ends up making approximations, but these approximations can only be in one direction, or else analysis results can’t be used to justify compiler optimizations. The paper leaves some work to be done in making this all practical in a production compiler, but it looks to me like this should mainly be a matter of engineering.
A property of dataflow transfer functions is that they lose precision across instruction boundaries. We can mitigate this by finding collections of instructions commonly found together (such as those implementing a minimum or maximum operation) and synthesizing a transfer function for the aggregate operation. We can also gain back precision by special-casing the situation where both arguments to an instruction come from the same source. We don’t tend to do these things when writing dataflow transfer functions by hand, but in an automated workflow they would be no problem at all. Another thing that we’d like to automate is creating efficient and precise product operators that allow dataflow analyses to exchange information with each other.
Given a collection of dataflow transfer functions, creating a dataflow analysis is a matter of plugging them into a generic dataflow framework that applies transfer functions until a fixpoint is reached. This is all old hat. The result of a dataflow analysis is a collection of dataflow facts attached to each instruction in a file that is being compiled.
To automatically make use of dataflow facts to drive optimizations, we can use a superoptimizer. For example, we taught Souper to use several of LLVM’s dataflow results. This is easy stuff compared to creating a superoptimizer in the first place: basically, we can reuse the same formalization of the dataflow analysis that we already created in order to synthesize transfer functions. Then, the generalization engine also needs to fully support dataflow analyses; our Hydra tool already does a great job at this, there are plenty of details in the paper.
Now that we’ve closed the loop, let’s ask whether there are interesting dataflow analyses missing from LLVM, that we should implement? Of course I don’t know for sure, but one such domain that I’ve long been interested in trying out is “congruences” where for a variable v, we try to prove that it always satisfies v = ax+b, for a pair of constants a and b. This sort of domain is useful for tracking values that point into an array of structs, where a is the struct size and b is the offset of one of its fields.
Our current generation of production compilers, at the implementation level, is somewhat divorced from the mathematical foundations of compilation. In the future we’ll instead derive parts of compiler implementations — such as dataflow analyses and peephole optimizations — directly from these foundations.
ScreenAnarchy: Calgary Underground 2024 Review: HUMANE, The Family That Slays Together Stays Together
 Apocalypses in Canadian cinema tend to occur in slow motion, and have a subversive touch of quiet absurdity. The two undisputed classics of the genre are Don McKellar’s Last Night, and Bruce McDonald’s Pontypool. Caitlin Cronenberg aims for that lofty territory with her debut feature film, Humane.
Set sometime in the near future, in late-stage climate crisis, citizens need solar umbrellas to go outside, and put protective film on the inside of their cars to keep the toxic sun out. Much of the world has collapsed into chaos, but Canada still limps along civilly, due to a government which has implemented a voluntary suicide programs called “Enlistment.” People can sign up to remove themselves from the population for a cash settlement that goes...
Apocalypses in Canadian cinema tend to occur in slow motion, and have a subversive touch of quiet absurdity. The two undisputed classics of the genre are Don McKellar’s Last Night, and Bruce McDonald’s Pontypool. Caitlin Cronenberg aims for that lofty territory with her debut feature film, Humane.
Set sometime in the near future, in late-stage climate crisis, citizens need solar umbrellas to go outside, and put protective film on the inside of their cars to keep the toxic sun out. Much of the world has collapsed into chaos, but Canada still limps along civilly, due to a government which has implemented a voluntary suicide programs called “Enlistment.” People can sign up to remove themselves from the population for a cash settlement that goes...
Disquiet: Scratch Pad: Wenders, Frisell, Manhattan
I do this manually at the end of each week: collating (and sometimes lightly editing) most of the recent little comments I’ve made on social media, which I think of as my public scratch pad. Some end up on Disquiet.com earlier, sometimes in expanded form. These days I mostly hang out on Mastodon (at post.lurk.org/@disquiet), and I’m also trying out a few others. I take weekends and evenings off social media.
▰ The sole downside to opening the living room window is the terrible music that people play in their cars
▰ I saw Brad Mehldau two weeks ago. I’m seeing Bill Frisell and Hank Roberts together in a few days. Both times as part of larger ensembles (quintet and sextet respectively). Life is pretty good.
▰ Are there any recordings of Bill Frisell and Brad Mehldau playing together other than those on the soundtrack to the Wim Wenders film Million Dollar Hotel?
▰ It’s extraordinary that a subset of the consumer electronics manufacturing class happily foresees a future in which everyone openly records every interaction, including face-to-face ones. It’s a glimpse at a potential radical realignment of what it means to speak not only in public but in private.
▰ Amazing how those AI discussion summary bots that join calls can totally diminish the small talk and casual interactions. It’s like someone purposefully set out to make video calls worse.
▰ I just noticed that April 14 isn’t just a favorite holiday of electronic music fans. It also was the first time, back in 2016, that the Disquiet Junto projects began appearing as part of the Lines BBS, after 223 weeks just on SoundCloud, Disquiet.com, and social media.
▰ If keeping a journal is a struggle for you, write a letter. You needn’t even mail it. Think of an ideal audience — friend or family, alive or not — and write to them. Much of my journal is excerpts of stuff I say to people in emails and texts I’d never have written had it not been intended for them.
▰ Honk if an email subject line about “markdown” makes you think file type not cost reduction
▰ Alert: We are now 25 weeks from the 666th consecutive weekly Disquiet Junto project.
▰ There’s a unique memory hole related to software that’s sunsetted before there’s a Wikipedia page to document it having existed in the first place
▰ My hotel room’s one, tiny window did provide a view of the Empire State Building.

▰ The spellcheck in Slack doesn’t recognize “Akihabara.” Oh, neither does this one. Must be system-wide.
▰ After seeing that new Taylor Swift album art, I kinda expected a Joy Division cover or two
▰ I saw a lot of mysterious doorways in Manhattan. This one was a definite favorite:

▰ When you get home from a vacation and start receiving the inevitable email offers from restaurants, bookstores, and other places you visited and are now 3,000 miles away from
▰ End of day:

Schneier on Security: New Lattice Cryptanalytic Technique
A new paper presents a polynomial-time quantum algorithm for solving certain hard lattice problems. This could be a big deal for post-quantum cryptographic algorithms, since many of them base their security on hard lattice problems.
A few things to note. One, this paper has not yet been peer reviewed. As this comment points out: “We had already some cases where efficient quantum algorithms for lattice problems were discovered, but they turned out not being correct or only worked for simple special cases.” I expect we’ll learn more about this particular algorithm with time. And, like many of these algorithms, there will be improvements down the road.
Two, this is a quantum algorithm, which means that it has not been tested. There is a wide gulf between quantum algorithms in theory and in practice. And until we can actually code and test these algorithms, we should be suspicious of their speed and complexity claims.
And three, I am not surprised at all. We don’t have nearly enough analysis of lattice-based cryptosystems to be confident in their security.
EDITED TO ADD (4/20): The paper had a significant error, and has basically been retracted. From the new abstract:
Note: Update on April 18: Step 9 of the algorithm contains a bug, which I don’t know how to fix. See Section 3.5.9 (Page 37) for details. I sincerely thank Hongxun Wu and (independently) Thomas Vidick for finding the bug today. Now the claim of showing a polynomial time quantum algorithm for solving LWE with polynomial modulus-noise ratios does not hold. I leave the rest of the paper as it is (added a clarification of an operation in Step 8) as a hope that ideas like Complex Gaussian and windowed QFT may find other applications in quantum computation, or tackle LWE in other ways.
Disquiet: Vinyl Surfacing of Siren Recording

Way back in March 2013, I recorded the Tuesday noon siren that used to resound throughout San Francisco. The siren has since been silenced for municipal budgetary reasons, but the recording lives on. It is one my most listened-to tracks on SoundCloud, and it’s been sampled by various musicians over time — as have other recordings of the siren that circulate on the internet.
And now, for the first time, my recording has appeared on a vinyl record album. Neil Stringfellow, who records as Audio Obscura, opens his new full-length album, Acid Field Recordings in Dub, with a track titled “Through Nuclear Skies,” which begins with my siren recording, before deep dubby sounds take over.
Embedding hasn’t been working for me lately, so head to audioobscura.bandcamp.com to listen. And here’s the original audio:
Open Culture: Daniel Dennett Presents the 4 Biggest Ideas in Philosophy in One of His Final Videos (RIP)

A week ago, Big Think released this video featuring philosopher Daniel Dennett talking about the four biggest ideas in philosophy. Today, we learned that he passed away at age 82. The New York Times obituary for Dennett reads: “Espousing his ideas in best sellers, he insisted that religion was an illusion, free will was a fantasy and evolution could only be explained by natural selection.” “Mr. Dennett combined a wide range of knowledge with an easy, often playful writing style to reach a lay public, avoiding the impenetrable concepts and turgid prose of many other contemporary philosophers. Beyond his more than 20 books and scores of essays, his writings even made their way into the theater and onto the concert stage.”
Above, Dennett, a long-time philosophy professor at Tufts University, outlines the “four eras he evolved through on his own journey as a philosopher: classical philosophy, evolutionary theory, memetic theory, and the intentional stance. Each stage added depth to his perspective and understanding… Dennett’s key takeaway is a request for philosophers to reevaluate their methodologies, urging modern-day thinkers to embrace the insights offered by new scientific discoveries. By combining the existential and theoretical viewpoints of philosophers with the analytical and evidential perspective of scientists, we can begin to fully and accurately interpret the world around us.”
To help you delve a little deeper into Daniel Dennett’s world, we’ve also posted below a vintage TED video where the philosopher discusses the illusion of consciousness. We would also encourage you to explore the Dennett items in the Relateds below.

Related Content
Daniel Dennett Presents Seven Tools For Critical Thinking
How to Argue With Kindness and Care: 4 Rules from Philosopher Daniel Dennett
Daniel Dennett and Cornel West Decode the Philosophy of The Matrix
Hear What It Sounds Like When Philosopher Daniel Dennett’s Brain Activity Gets Turned into Music
Daniel Lemire's blog: How quickly can you break a long string into lines?
Suppose that you receive a long string and you need to break it down into lines. Consider the simplified problems where you need to break the string into segments of (say) 72 characters. It is a relevant problem if your string is a base64 string or a Fortran formatted statement.
The problem could be a bit complicated because you might need consider the syntax. So the speed of breaking into a new line every 72 characters irrespective of the content provides an upper bound on the performance of breaking content into lines.
The most obvious algorithm could be to copy the content, line by line:
void break_lines(char *out, const char *in, size_t length, size_t line_length) { size_t j = 0; size_t i = 0; for (; i + line_length <= length; i += line_length) { memcpy(out + j, in + i, line_length); out[j+line_length] = '\n'; j += line_length + 1; } if (i < length) { memcpy(out + j, in + i, length - i); } }
Copying data in blocks in usually quite fast unless you are unlucky and you trigger aliasing. However, allocating a whole new buffer could be wasteful, especially if you only need to extend the current buffer by a few bytes.
A better option could thus be to do the work in-place. The difficulty is that if you load the data from the current array, and then write it a bit further away, you might be overwriting the data you need to load next. A solution is to proceed in reverse: start from the end… move what would be the last line off by a few bytes, then move the second last line and so forth. Your code might look like the following C function:
void break_lines_inplace(char *in, size_t length, size_t line_length) { size_t left = length % line_length; size_t i = length - left; size_t j = length + length / line_length - left; memmove(in + j, in + i, left); while (i >= line_length) { i -= line_length; j -= line_length + 1; memmove(in + j, in + i, line_length); in[j+line_length] = '\n'; } }
I wrote a benchmark. I report the results only for a 64KB input. Importantly, my numbers do not include memory allocation which is separate.
A potentially important factor is whether we allow function inlining: without inlining, the compiler does not know the line length at compile-time and cannot optimize accordingly.
Your results will vary, but here are my own results:
| method | Intel Ice Lake, GCC 12 | Apple M2, LLVM 14 |
|---|---|---|
| memcpy | 43 GB/s | 70 GB/s |
| copy | 25 GB/s | 40 GB/s |
| copy (no inline) | 25 GB/s | 37 GB/s |
| in-place | 25 GB/s | 38 GB/s |
| in-place (no inline) | 25 GB/s | 38 GB/s |
In my case, it does not matter whether we do the computation in-place or not. The in-place approach generates more instructions but we are not limited by the number of instructions.
At least in my results, I do not see a large effect from inlining. In fact, for the in-place routine, there appears to be no effect whatsoever.
Roughly speaking, I achieve a bit more than half the speed as that of a memory copy. We might be limited by the number of loads and stores. There might be a clever way to close the gap.
Penny Arcade: Stranger Danger
I considered some more Vault 77, but the new Transformers trailer had just hit and we talked about that instead. I always think that I like Transformers a normal amount, that there is something universal in these warring cults of conscious machines, but I think that I might actually like them way more than other people and quite possibly I like them a weird amount.
Planet Lisp: Joe Marshall: Plaformer Game Tutorial
I was suprised by the interest in the code I wrote for learning the platformer game. It wasn’t the best Lisp code. I just uploaded what I had.
But enough people were interested that I decided to give it a once over. At https://github.com/jrm-code-project/PlatformerTutorial I have a rewrite where each chapter of the tutorial has been broken off into a separate git branch. The code is much cleaner and several kludges and idioticies were removed (and I hope none added).
Saturday Morning Breakfast Cereal: Saturday Morning Breakfast Cereal - Red

Click here to go see the bonus panel!
Hovertext:
This is the right opportunity to remind you that every SMBC is available as a high-quality print to adorn your home or office.
Today's News:
ScreenAnarchy: PICNIC AT HANGING ROCK 4K Review: Wow. Wow. Wow.
 Peter Weir's magical mystery tour from 1975 looks like it was released today in the incredible-looking Criterion Collection 4K edition. This is why Australia is called "Oz."
Peter Weir's magical mystery tour from 1975 looks like it was released today in the incredible-looking Criterion Collection 4K edition. This is why Australia is called "Oz."
Schneier on Security: Friday Squid Blogging: Squid Trackers
A new bioadhesive makes it easier to attach trackers to squid.
Note: the article does not discuss squid privacy rights.
As usual, you can also use this squid post to talk about the security stories in the news that I haven’t covered.
Read my blog posting guidelines here.


























































Ideas: “Sometimes I think this city is trying to kill me…”
“Sometimes I think this city is trying to kill me…” That’s what a man on the margins once told Robin Mazumder who left his healthcare career behind to become an environmental neuroscientist. He now measures stress, to advocate for wider well-being in better-designed cities.
Michael Geist: Debating the Online Harms Act: Insights from Two Recent Panels on Bill C-63

The Online Harms Act has sparked widespread debate over the past six weeks. I’ve covered the bill in a trio of Law Bytes podcast (Online Harms, Canada Human Rights Act, Criminal Code) and participated in several panels focused on the issue. Those panels are posted below. First, a panel titled the Online Harms Act: What’s Fact and What’s Fiction, sponsored by CIJA that included Emily Laidlaw, Richard Marceau and me. It paid particular attention to the intersection between the bill and online hate.
Second, a panel titled Governing Online Harms: A Conversation on Bill C-63, sponsored by the University of Ottawa Centre for Law, Technology and Society that covered a wide range of issues and included Emily Laidlaw, Florian Martin-Bariteau, Jane Bailey, Sunil Gurmukh, and me.
The post Debating the Online Harms Act: Insights from Two Recent Panels on Bill C-63 appeared first on Michael Geist.
Ideas: The "Reconciliation" Generation: Indigenous Youth and the Future for Indigenous People
Indigenous activist Riley Yesno addresses the hopes, disappointments, accomplishments and misuses of ‘reconciliation’ in post-TRC Canada. The Anishnaabe scholar says Indigenous youth who came of age at this time are "meant to be responsible for seeing it through to its next stage."













Ideas: The history of bombing civilians — and why it’s still a military tactic
The bombing of civilians has been called one of the "great scandals" of modern warfare. So why, despite nearly a century of drafting laws and signing conventions protecting the sanctity of human life, does bombing civilians remain a widespread military tactic?
Tea Masters: Purple Da Yi 2003 vs loose Gushu from early 2000s


The taste also has lots of similarities, but I find the loose gushu a little bit thicker in taste and more harmonious. So, the Da Yi has some strong points, but the loose gushu still comes on top if your focus is purity and a thick gushu taste. And the price of the loose puerh also makes it a winner!

The Universe of Discourse: Try it and see
I thought about this because of yesterday's article about the person who needed to count the 3-colorings of an icosahedron, but didn't try constructing any to see what they were like.
Around 2015 Katara, then age 11, saw me writing up my long series of articles about the Cosmic Call message and asked me to explain what the mysterious symbols meant. (It's intended to be a message that space aliens can figure out even though they haven't met us.)

I said “I bet you could figure it out if you tried.” She didn't believe me and she didn't want to try. It seemed insurmountable.
“Okay,” I said, handing her a printed copy of page 1. “Sit on the chaise there and just look at it for five minutes without talking or asking any questions, while I work on this. Then I promise I'll explain everything.”
She figured it out in way less than five minutes. She was thrilled to discover that she could do it.
I think she learned something important that day: A person can accomplish a lot with a few minutes of uninterrupted silent thinking, perhaps more than they imagine, and certainly a lot more than if they don't try.
I think there's a passage somewhere in Zen and the Art of Motorcycle Maintenance about how, when you don't know what to do next, you should just sit with your mouth shut for a couple of minutes and see if any ideas come nibbling. Sometimes they don't. But if there are any swimming around, you won't catch them unless you're waiting for them.
CreativeApplications.Net: gr1dflow – Exploring recursive ontologies

gr1dflow is a collection of artworks created through code, delving into the world of computational space. While the flowing cells and clusters showcase the real-time and dynamic nature of the medium, the colours and the initial configuration of the complex shapes are derived from blockchain specific metadata associated with the collection.
Submitted by: 0xStc
Category: Member Submissions
Tags: audiovisual / blockchain / generative / glsl / NFT / realtime / recursion
People: Agoston Nagy
Michael Geist: The Law Bytes Podcast, Episode 199: Boris Bytensky on the Criminal Code Reforms in the Online Harms Act

The Online Harms Act – otherwise known as Bill C-63 – is really at least three bills in one. The Law Bytes podcast tackled the Internet platform portion of the bill last month in an episode with Vivek Krishnamurthy and then last week Professor Richard Moon joined to talk about the return of Section 13 of the Canada Human Rights Act. Part three may the most controversial: the inclusion of Criminal Code changes that have left even supporters of the bill uncomfortable.
Boris Bytensky of the firm Bytensky Shikhman has been a leading Canadian criminal law lawyer for decades and currently serves as President of the Criminal Lawyers’ Association. He joins the podcast to discuss the bill’s Criminal Code reforms as he identifies some of the practical implications that have thus far been largely overlooked in the public debate.
The podcast can be downloaded here, accessed on YouTube, and is embedded below. Subscribe to the podcast via Apple Podcast, Google Play, Spotify or the RSS feed. Updates on the podcast on Twitter at @Lawbytespod.
Credits:
W5, A Shocking Upsurge of Hate Crimes in Canada
The post The Law Bytes Podcast, Episode 199: Boris Bytensky on the Criminal Code Reforms in the Online Harms Act appeared first on Michael Geist.
Tea Masters: Another puerh comparison: Yiwu from 2003 vs. DaYi purple cake from 2003
 |
| Yiwu 2003 vs DaYi purple 2003 |

Project Gus: Unremarkable Kona Progress
I've been holding off posting as I haven't had any major breakthroughs with the Kona Electric reversing project. However, I haven't sat totally idle...
On-car testing
Last post the Kona motor started to spin, but without a load attached it was spinning out of control! Even in Neutral, the motor …
The Shape of Code: Average lines added/deleted by commits across languages
Are programs written in some programming language shorter/longer, on average, than when written in other languages?
There is a lot of variation in the length of the same program written in the same language, across different developers. Comparing program length across different languages requires a large sample of programs, each implemented in different languages, and by many different developers. This sounds like a fantasy sample, given the rarity of finding the same specification implemented multiple times in the same language.
There is a possible alternative approach to answering this question: Compare the size of commits, in lines of code, for many different programs across a variety of languages. The paper: A Study of Bug Resolution Characteristics in Popular Programming Languages by Zhang, Li, Hao, Wang, Tang, Zhang, and Harman studied 3,232,937 commits across 585 projects and 10 programming languages (between 56 and 60 projects per language, with between 58,533 and 474,497 commits per language).
The data on each commit includes: lines added, lines deleted, files changed, language, project, type of commit, lines of code in project (at some point in time). The paper investigate bug resolution characteristics, but does not include any data on number of people available to fix reported issues; I focused on all lines added/deleted.
Different projects (programs) will have different characteristics. For instance, a smaller program provides more scope for adding lots of new functionality, and a larger program contains more code that can be deleted. Some projects/developers commit every change (i.e., many small commit), while others only commit when the change is completed (i.e., larger commits). There may also be algorithmic characteristics that affect the quantity of code written, e.g., availability of libraries or need for detailed bit twiddling.
It is not possible to include project-id directly in the model, because each project is written in a different language, i.e., language can be predicted from project-id. However, program size can be included as a continuous variable (only one LOC value is available, which is not ideal).
The following R code fits a basic model (the number of lines added/deleted is count data and usually small, so a Poisson distribution is assumed; given the wide range of commit sizes, quantile regression may be a better approach):
alang_mod=glm(additions ~ language+log(LOC), data=lc, family="poisson")
dlang_mod=glm(deletions ~ language+log(LOC), data=lc, family="poisson")
Some of the commits involve tens of thousands of lines (see plot below). This sounds rather extreme. So two sets of models are fitted, one with the original data and the other only including commits with additions/deletions containing less than 10,000 lines.
These models fit the mean number of lines added/deleted over all projects written in a particular language, and the models are multiplicative. As expected, the variance explained by these two factors is small, at around 5%. The two models fitted are (code+data):
 or
or  , and
, and  or
or  , where the value of
, where the value of  is listed in the following table, and
is listed in the following table, and  is the number of lines of code in the project:
is the number of lines of code in the project:
Original 0 < lines < 10000
Language Added Deleted Added Deleted
C 1.0 1.0 1.0 1.0
C# 1.7 1.6 1.5 1.5
C++ 1.9 2.1 1.3 1.4
Go 1.4 1.2 1.3 1.2
Java 0.9 1.0 1.5 1.5
Javascript 1.1 1.1 1.3 1.6
Objective-C 1.2 1.4 2.0 2.4
PHP 2.5 2.6 1.7 1.9
Python 0.7 0.7 0.8 0.8
Ruby 0.3 0.3 0.7 0.7
These fitted models suggest that commit addition/deletion both increase as project size increases, by around  , and that, for instance, a commit in Go adds 1.4 times as many lines as C, and delete 1.2 as many lines (averaged over all commits). Comparing adds/deletes for the same language: on average, a Go commit adds
, and that, for instance, a commit in Go adds 1.4 times as many lines as C, and delete 1.2 as many lines (averaged over all commits). Comparing adds/deletes for the same language: on average, a Go commit adds  lines, and deletes
lines, and deletes  lines.
lines.
There is a strong connection between the number of lines added/deleted in each commit. The plot below shows the lines added/deleted by each commit, with the red line showing a fitted regression model  (code+data):
(code+data):
What other information can be included in a model? It is possible that project specific behavior(s) create a correlation between the size of commits; the algorithm used to fit this model assumes zero correlation. The glmer function, in the R package lme4, can take account of correlation between commits. The model component (language | project) in the following code adds project as a random effect on the language variable:
del_lmod=glmer(deletions ~ language+log(LOC)+(language | project), data=lc_loc, family=poisson)
It takes around 24hr of cpu time to fit this model, which means I have not done much experimentation...
The Universe of Discourse: Stuff that is and isn't backwards in Australia
I recently wrote about things that are backwards in Australia. I made this controversial claim:
The sun in the Southern Hemisphere moves counterclockwise across the sky over the course of the day, rather than clockwise. Instead of coming up on the left and going down on the right, as it does in the Northern Hemisphere, it comes up on the right and goes down on the left.
Many people found this confusing and I'm not sure our minds met on this. I am going to try to explain and see if I can clear up the puzzles.
“Which way are you facing?” was a frequent question. “If you're facing north, it comes up on the right, not the left.”
(To prevent endless parenthetical “(in the Northern Hemisphere)” qualifications, the rest of this article will describe how things look where I live, in the northern temperate zones. I understand that things will be reversed in the Southern Hemisphere, and quite different near the equator and the poles.)
Here's what I think the sky looks like most of the day on most of the days of the year:
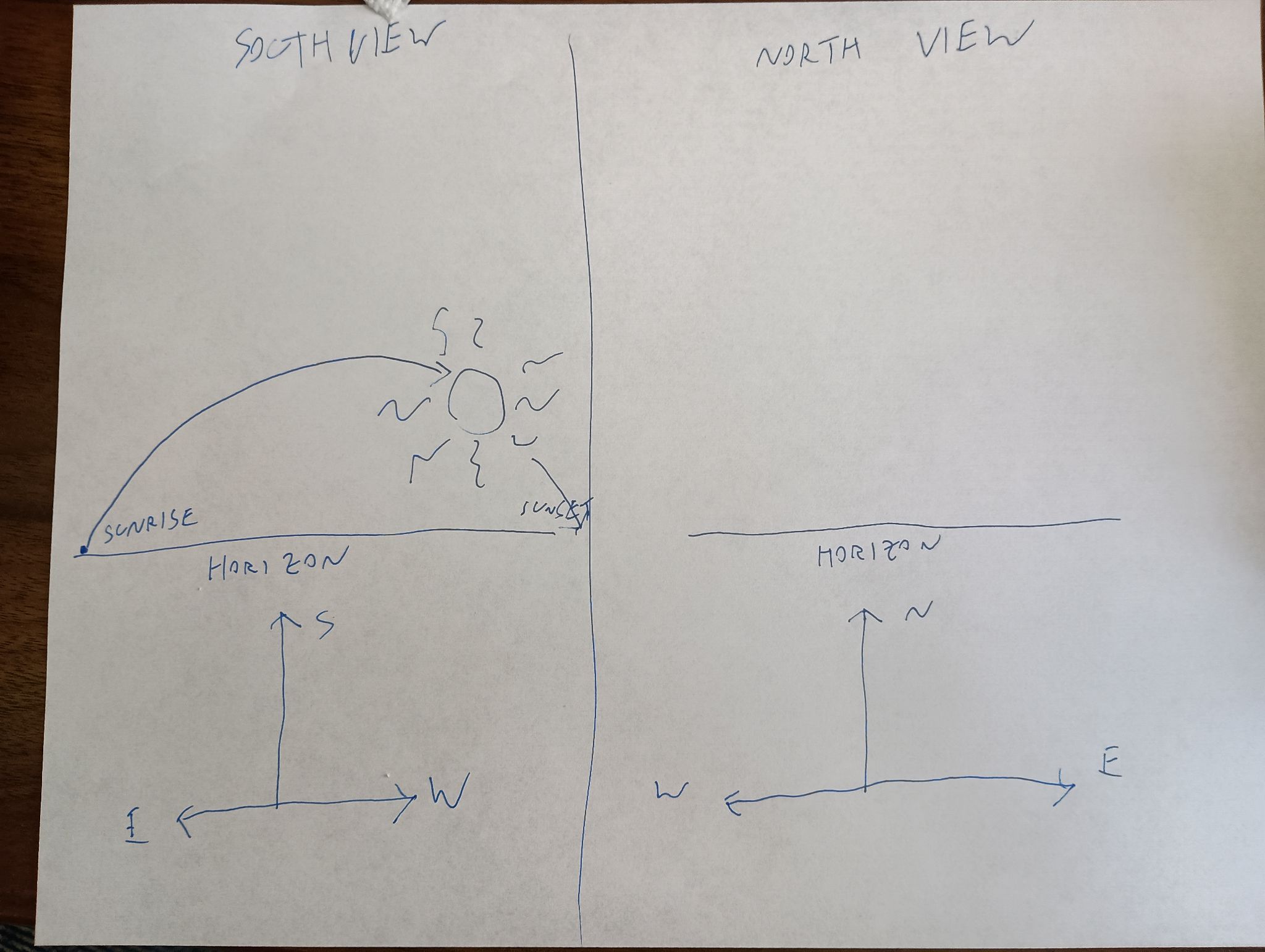
The sun is in the southern sky through the entire autumn, winter, and spring. In summer it is sometimes north of the celestial equator, for up to a couple of hours after sunrise and before sunset, but it is still in the southern sky most of the time. If you are watching the sun's path through the sky, you are looking south, not north, because if you are looking north you do not see the sun, it is behind you.
Some people even tried to argue that if you face north, the sun's path is a counterclockwise circle, rather than a clockwise one. This is risible. Here's my grandfather's old grandfather clock. Notice that the hands go counterclockwise! You study the clock and disagree. They don't go counterclockwise, you say, they go clockwise, just like on every other clock. Aha, but no, I say! If you were standing behind the clock, looking into it with the back door open, then you would clearly see the hands go counterclockwise! Then you kick me in the shin, as I deserve.
Yes, if you were to face away from the sun, its path could be said to be counterclockwise, if you could see it. But that is not how we describe things. If I say that a train passed left to right, you would not normally expect me to add “but it would have been right to left, had I been facing the tracks”.
At least one person said they had imagined the sun rising directly ahead, then passing overhead, and going down in back. Okay, fair enough. You don't say that the train passed left to right if you were standing on the tracks and it ran you down.
Except that the sun does not pass directly overhead. It only does that in the tropics. If this person were really facing the sun as it rose, and stayed facing that way, the sun would go up toward their right side. If it were a train, the train tracks would go in a big curve around their right (south) side, from left to right:

Mixed gauge track (950 and 1435mm) at Sassari station, Sardinia, 1996 by user Afterbrunel, CC BY-SA 3.0 DEED, via Wikimedia Commons. I added the big green arrows.
_at_Sassari_station,_Sardinia,_1996.jpg){kind=link}
After the train passed, it would go back the other way, but they wouldn't be able see it, because it would be behind them. If they turned around to watch it go, it would still go left to right:

And if they were to turn to follow it over the course of the day, they would be turning left to right the whole time, and the sun would be moving from left to right the whole time, going up on the left and coming down on the right, like the hands of a clock — “clockwise”, as it were.
One correspondent suggested that perhaps many people in technologically advanced countries are not actually familiar with how the sun and moon move, and this was the cause of some of the confusion. Perhaps so, it's certainly tempting to dismiss my critics as not knowing how the sun behaves. The other possibility is that I am utterly confused. I took Observational Astronomy in college twice, and failed both times.
Anyway, I will maybe admit that “left to right” was unclear. But I will not recant my claim that the sun moves clockwise. E pur si muove in senso orario.
Sundials
Here I was just dead wrong. I said:
In the Northern Hemisphere, the shadow of a sundial proceeds clockwise, from left to right.
Absolutely not, none of this is correct. First, “left to right”. Here's a diagram of a typical sundial:

It has a sticky-up thing called a ‘gnomon’ that casts a shadow across the numbers, and the shadow moves from left to right over the course of the day. But obviously the sundial will work just as well if you walk around and look at it from the other side:

It still goes clockwise, but now clockwise is right to left instead of left to right.
It's hard to read because the numerals are upside down? Fine, whatever:

Here, unlike with the sun, “go around to the other side” is perfectly reasonable.
Talking with Joe Ardent, I realized that not even “clockwise” is required for sundials. Imagine the south-facing wall of a building, with the gnomon sticking out of it perpendicular. When the sun passes overhead, the gnomon will cast a shadow downwards on the wall, and the downward-pointing shadow will move from left to right — counterclockwise — as the sun makes its way from east to west. It's not even far-fetched. Indeed, a search for “vertical sundials” produced numerous examples:

Sundial on the Moot Hall by David Dixon, CC BY 2.0 https://creativecommons.org/licenses/by/2.0, via Wikimedia Commons and Geograph.
{kind=link}
Winter weather on July 4
Finally, it was reported that there were complaints on Hacker News that Australians do not celebrate July 4th. Ridiculous! All patriotic Americans celebrate July 4th.
Planet Lisp: Paolo Amoroso: Testing the Practical Common Lisp code on Medley
When the Medley Interlisp Project began reviving the system around 2020, its Common Lisp implementation was in the state it had when commercial development petered out in the 1990s, mostly prior to the ANSI standard.
Back then Medley Common Lisp mostly supported CLtL1 plus CLOS and the condition system. Some patches submitted several years later to bring the language closer to CLtL2 needed review and integration.
Aside from these general areas there was no detailed information on what Medley missed or differed from ANSI Common Lisp.
In late 2021 Larry Masinter proposed to evaluate the ANSI compatibility of Medley Common Lisp by running the code of popular Common Lisp books and documenting any divergences. In March of 2024 I set to work to test the code of the book Practical Common Lisp by Peter Seibel.
I went over the book chapter by chapter and completed a first pass, documenting the effort in a GitHub issue and a series of discussion posts. In addition I updated a running list of divergences from ANSI Common Lisp.
Methodology
Part of the code of the book is contained in the examples in the text and the rest in the downloadable source files, which constitute some more substantial projects.
To test the code on Medley I evaluated the definitions and expressions at a Xerox Common Lisp Exec, noting any errors or differences from the expected outcomes. When relevant source files were available I loaded them prior to evaluating the test expressions so that any required definitions and dependencies were present. ASDF hasn't been ported to Medley, so I loaded the files manually.
Adapting the code
Before running the code I had to apply a number of changes. I filled in any missing function and class definitions the book leaves out as incidental to the exposition. This also involved adding appropriate function calls and object instantiations to exercise the definitions or produce the expected output.
The source files of the book needed adaptation too due to the way Medley handles pure Common Lisp files.
Skipped code
The text and source files contain also code I couldn't run because some features are known to be missing from Medley, or key dependencies can't be fulfilled. For example, a few chapters rely on the AllegroServe HTTP server which doesn't run on Medley. Although Medley does have a XNS network stack, providing the TCP/IP network functions AllegroServe assumes would be a major project.
Some chapters depend on code in earlier chapters that uses features not available in Medley Common Lisp, so I had to skip those too.
Findings
Having completed the first pass over Practical Common Lisp, my initial impression is Medley's implementation of Common Lisp is capable and extensive. It can run with minor or no changes code that uses most basic and intermediate Common Lisp features.
The majority of the code I tried ran as expected. However, this work did reveal significant gaps and divergences from ANSI.
To account for the residential environment and other peculiarities of Medley, packages need to be defined in a specific way. For example, some common defpackage keyword arguments differ from ANSI. Also, uppercase strings seem to work better than keywords as package designators.
As for the gaps the loop iteration macro, symbol-macrolet, the #p reader macro, and other features turned out to be missing or not work.
While the incompatibilities with ANSI Common Lisp are relativaly easy to address or work around, what new users may find more difficult is understanding and using the residential environment of Medley.
Bringing Medley closer to ANSI Common Lisp
To plug the gaps this project uncovered Larry ported or implemented some of the missing features and fixed a few issues.
He ported a loop implementation which he's enhancing to add missing functionality like iterating over hash tables. Iterating over packages, which loop lacks at this time, is trickier. More work went into adding #p and an experimental symbol-macrolet.
Reviewing and merging the CLtL2 patches is still an open issue, a major project that involves substantial effort.
Future work and conclusion
When the new features are ready I'll do a second pass to check if more of the skipped code runs. Another outcome of the work may be the beginning of a test suite for Medley Common Lisp.
Regardless of the limitations, what the project highlighted is Medley is ready as a development environment for writing new Common Lisp code, or porting libraries and applications of small to medium complexity.
Discuss... Email | Reply @amoroso@fosstodon.org
MattCha's Blog: 1999-2003 Mr Chen’s JiaJi Green Mark

This 1999-2003 Mr Chen’s JaiJi Green Ink sample came free with the purchase of the 1999 Mr Chen Daye ZhengShan MTF Special Order. I didn’t go to the site so blind to the price and description and tried it after a session of the ZhongShan MTF Special Order…
Dry leaves have a dry woody dirt faint taste.
Rinsed leaves have a creamy sweet odour.
First infusion has a sweet watery onset there is a return of sweet woody slight warm spice. Sweet, simple, watery and clean in this first infusion.
Second infusion has a sweet watery simple woody watery sweet taste. Slight woody incense and slight fresh fruity taste. Cooling mouth. Sweet bread slight faint candy aftertaste. Slight drying mouthfeel.
Third infusions has a woody dry wood onset with a dry woody sweet kind of taste. The return is a bready candy with sweet aftertaste. Tastes faintly like red rope licorice. Dry mouthfeeling now. Somewhat relaxing qi. Mild but slight feel good feeling. Mild Qi feeling.

Fourth infusion is left to cool and is creamy sweet watery with a faint background wood and even faint incense. Simple sweet clean tastes. Thin dry mouthfeel.
Fifth infusion is a slight creamy sweet watery slight woody simple sweet pure tasting. left to cool is a creamy sweet some lubricant watery sweetness.
Sixth has an incense creamy sweet talc woody creamy more full sweetness initially. Creamy sweetness watery mild Qi. Enjoyable and easy drinking puerh.
Seventh has a sweet woody leaf watery taste with an incense woody watery base. The mouthfeel is slightly dry and qi is pretty mild and agreeable.
Eighth infusion is a woody watery sweet with subtle incense warm spice. Mild dry mouthfeel.
Ninth infusion has a woody incense onset with sweet edges. Dry flat mouthfeel and mild qi.
Tenth I put into long mug steepings… it has a dirt woody bland slight bitter taste… not much for sweetness anymore.
Overnight infusion has a watery bland, slight dirt, slight sweet insipid taste.

This is a pretty simple and straightforward dry stored aged sheng. Sweet woody incense taste with mild dry and mild relaxing feel good qi. On a busy day at work I appreciated its steady aged simplicity. I go to the site and look at the price and description and I couldn’t really agree more. The price is a bit lower than I thought and the description is dead on!
Vs 1999 Mr Chen’s Daye ZhengShan MTF Special Order- despite coming from the same collector, being both dry stored, and being the same approx age these are very different puerh. The MTF special order is much more complex in taste, very very sweet and has much more powerful space out Qi. This JaiJi Green ink is satisfying enough but not so fancy complex or mind-bending. It’s more of an aged dry storage drinker.
After a session of the 1999 Mr Chen Daye ZhengShan I did a back to back with 2001 Naked Yiwu from TeasWeLike but they are also completely differ puerh… the Nake Yiwu was much more condensed, present, and powerful in taste with sweet tastes, resin wood, and smoke incense. It’s more aggressive and forward and feels less aged than the 1999 ZhengShan MTF Special Order but in the same way it can be more satisfying especially for the price which seems like a pretty good deal. I suppose all three of these are good value dispite the totally different vibes of each.
Pictured is Left 2001 Naked Yiwu from TeasWeLike, Middle 1999 Mr Chen’s Daye ZhengShan MTF, Right 2001-1999 Me Chen’s JiaJi Green Ink.
Peace
Daniel Lemire's blog: Science and Technology links (April 13 2024)
-
-
- Our computer hardware exchange data using a standard called PCI Express. Your disk, your network and your GPU are limited by what PCI Express can do. Currently, it means that you are limited to a few gigabytes per second of bandwidth. PCI Express is about to receive a big performance boost in 2025 when PCI Express 7 comes out: it will support bandwidth of up to 512 GB/s. That is really, really fast. It does not follow that your disks and graphics are going to improve very soon, but it provides the foundation for future breakthroughs.
- Sperm counts are down everywhere and the trend is showing no sign of slowing down. There are indications that it could be related to the rise in obesity.
- A research paper by Burke et al. used a model to predict that climate change could reduce world GPD (the size of the economy) by 23%. For reference, world GDP grows at a rate of about 3% a year (+/- 1%) so that a cost of 23% is about equivalent to 7 to 8 years without growth. It is much higher than prior predictions. Barket (2024) questions these results:
It is a complicated paper that makes strong claims. The authors use thousands of lines of code to run regressions containing over 500 variables to test a nonlinear model of temperature and growth for 166 countries and forecast economic growth out to the year 2100. Careful analysis of their work shows that they bury inconvenient results, use misleading charts to confuse readers, and fail to report obvious robustness checks. Simulations suggest that the statistical significance of their results is inflated. Continued economic growth at levels similar to what the world has experienced in recent years would increase the level of future economic activity by far more than Nordhaus’ (2018) estimate of the effect of warming on future world GDP. If warming does not affect the rate of economic growth, then the world is likely to be much richer in the future, with or without warming temperatures.
- The firm McKinsey reports finding statistically significant positive relations between the industry-adjusted earnings and the racial/ethnic diversity of their executives. Green and Hand (2024) fail to reproduce these results. They conclude: despite the imprimatur given to McKinsey’s studies, their results should not be relied on to support the view that US publicly traded firms can expect to deliver improved financial performance if they increase the racial/ethnic diversity of their executives.
- Corinth and Larrimore (2024) find that after adjusting for hours worked, Generation X and Millennials experienced a greater intergenerational increase in real market income than baby boomers.
-
Daniel Lemire's blog: Greatest common divisor, the extended Euclidean algorithm, and speed!
We sometimes need to find the greatest common divisor between two integers in software. The fastest way to compute the greatest common divisor might be the binary Euclidean algorithm. In C++20, it can be implemented generically as follows:
template <typename int_type> int_type binary_gcd(int_type u, int_type v) { if (u == 0) { return v; } if (v == 0) { return u; } auto shift = std::countr_zero(u | v); u >>= std::countr_zero(u); do { v >>= std::countr_zero(v); if (u > v) { std::swap(u, v); } v = v - u; } while (v != 0); return u << shift; }
The std::countr_zero function computes the “number of trailing zeroes” in an integer. A key insight is that this function often translates into a single instruction on modern hardware.
Its computational complexity is the number of bits in the largest of the two integers.
There are many variations that might be more efficient. I like an approach proposed by Paolo Bonzini which is simpler as it avoid the swap:
int_type binary_gcd_noswap(int_type u, int_type v) { if (u == 0) { return v; } if (v == 0) { return u; } auto shift = std::countr_zero(u | v); u >>= std::countr_zero(u); do { int_type t = v >> std::countr_zero(v); if (u > t) v = u - t, u = t; else v = t - u; } while (v != 0); return u << shift; }
The binary Euclidean algorithm is typically faster than the textbook Euclidean algorithm which has to do divisions (a slow operation), although the resulting code is pleasantly short:
template <typename int_type> int_type naive_gcd(int_type u, int_type v) { return (u % v) == 0 ? v : naive_gcd(v, u % v); }
There are cases where the naive GCD algorithm is faster. For example, if v divides u, which is always the case when v is 1, then the naive algorithm returns immediately whereas the binary GCD algorithm might require many steps if u is large.
I found interesting that there is a now a std::gcd function in the C++ standard library so you may not want to implement your own greatest-common-divisor if you are programming in modern C++.
For the mathematically inclined, there is also an extended Euclidean algorithm. It also computes the greatest common divisor, but also the Bézout coefficients. That is, given two integers a and b, it finds integers x and y such that x * a + y * b = gcd(a,b). I must admit that I never had any need for the extended Euclidean algorithm. Wikipedia says that it is useful to find multiplicative inverses in a module space, but the only multiplicative inverses I ever needed were computed with a fast Newton algorithm. Nevertheless, we might implement it as follows:
template <typename int_type> struct bezout { int_type gcd; int_type x; int_type y; }; // computes the greatest common divisor between a and b, // as well as the Bézout coefficients x and y such as // a*x + b*y = gcd(a,b) template <typename int_type> bezout<int_type> extended_gcd(int_type u, int_type v) { std::pair<int_type, int_type> r = {u, v}; std::pair<int_type, int_type> s = {1, 0}; std::pair<int_type, int_type> t = {0, 1}; while (r.second != 0) { auto quotient = r.first / r.second; r = {r.second, r.first - quotient * r.second}; s = {s.second, s.first - quotient * s.second}; t = {t.second, t.first - quotient * t.second}; } return {r.first, s.first, t.first}; }
There is also a binary version of the extended Euclidean algorithm although it is quite a bit more involved and it is not clear that it is can be implemented at high speed, leveraging fast instructions, when working on integers that fit in general-purpose registers. It is may beneficial when working with big integers. I am not going to reproduce my implementation, but it is available in my software repository.
To compare these functions, I decided to benchmark them over random 64-bit integers. I found interesting that the majority of pairs of random integers (about two thirds) were coprime, meaning that their greatest common divisor is 1. Mathematically, we would expect the ratio to be 6/pi2 which is about right empirically. At least some had non-trivial greatest common divisors (e.g., 42954).
Computing the greatest common divisor takes hundreds of instructions and hundreds of CPU cycle. If you somehow need to do it often, it could be a bottleneck.
I find that the std::gcd implementation which is part of the GCC C++ library under Linux is about as fast as the binary Euclidean function I presented. I have not looked at the implementation, but I assume that it might be well designed. The version that is present on the C++ library present on macOS (libc++) appears to be the naive implementation. Thus there is an opportunity to improve the lib++ implementation.
The extended Euclidean-algorithm implementation runs at about the same speed as a naive regular Euclidean-algorithm implementation, which is what you would expect. My implementation of the binary extended Euclidean algorithm is quite a bit slower and not recommended. I expect that it should be possible to optimize it further.
| function | GCC 12 + Intel Ice Lake | Apple LLVM + M2 |
|---|---|---|
| std::gcd | 7.2 million/s | 7.8 million/s |
| binary | 7.7 million/s | 12 million/s |
| binary (no swap) | 9.2 million/s | 14 million/s |
| extended | 2.9 million/s | 7.8 million/s |
| binary ext. | 0.7 million/s | 2.9 million/s |
It may seem surprising that the extended Euclidean algorithm runs at the same speed as std::gcd on some systems, despite the fact that it appears to do more work. However, the computation of the Bézout coefficient along with the greatest common divisor is not a critical path, and can be folded in with the rest of the computation on a superscalar processor… so the result is expected.
As part of the preparation of this blog post, I had initially tried writing a C++ module. It worked quite well on my MacBook. However, it fell part under Linux with GCC, so I reverted it back. I was quite happy at how using modules made the code simpler, but it is not yet sufficiently portable.
Credit: Thanks to Harold Aptroot for a remark about the probability of two random integers being prime.
MattCha's Blog: Complex Sweet Dry Storage: 1999 Mr Chen’s Daye ZhengShan MTF Special Order




Dry leaves have a sweet slight marsh peat odour to them.
Rinsed leaf has a leaf slight medicinal raison odour.
First infusion has a purfume medicinal fruity sweetness. There are notes of fig, cherries, longgan fruit nice complex onset with a were dry leaf base.
Second infusion has a woody slight purfume medical sweet cherry and fig taste. Nice dry storage base of slight mineral and leaf taste. Mouthfeel is a bit oily at first but slight silty underneath. There is a soft lingering sweetness returning of fruit with a woody base taste throughout. Slight warm chest with spacy head feeling.
Third infusion has a leafy woody maple syrup onset that gets a bit sweeter on return the sweetness is syrupy like stewed fruity with a leaf dry woody background that is throughout the profile. A more fruity pop of taste before some cool camphor on the breath. A silty almost dry mouthfeeling emerges after the initial slight oily syrup feeling. Slight warm chest and spacey mind slowing Qi.

Fourth infusion has a leaf medical onset with a slow emerging sweet taste that is quite sweet fruit on returning and sort of slowly builds up next to dry woody leaf and syrup medical taste. The cooled down infusion is a sweet creamy sweet syrupy. Spaced out Qi feeling.
5th infusion has a syrupy sweet woody medicinal creamy sweet with some fruity and maple syrup. Silty mouthfeel. Space out qi. The cooled down liquor is a woody maple sweet taste. Nice creamy almost fruity returning sweetness. Pear plum tastes underneath.
6th has a creamy oily watery sweetness with faint medicinal incense but mainly oily sweet taste. Fruity return with a slightly drier silty mouthfeel. Slight warming with nice space out Qi.
7th infusion has a woody pear leaf onset with an overall sweet pear oily onset.
8th has a soft pear woody leaf taste faint medicinal incense. Soft fading taste. Faint warmth and spacy mind.
9th has a mellow fruity sweetness with an oily texture and some incense medicinal mid taste. There is a woody leaf base. Mainly mild sweet no astringency or bitter. Oily watery mouthfeel.
10 this a long thermos steeping of the spent leaf.. it. Comes out oily and sweet with a strawberry sweetness subtle woody but mainly just fruity strawberry sweetness.

The overnight steeping is a sweet strawberry pure slight lubricating taste. Still sweet and lubricating. Very Yummy!
Peace
Tea Masters: Le Jinxuan 2024 annonce de bonnes récoltes de printemps






CreativeApplications.Net: Filigree – Matt Deslauriers

Category: NFT
Tags: generative
People: Matt DesLauriers
CreativeApplications.Net: WÆVEFORM – Paul Prudence

Category: NFT
Tags: generative
People: Paul Prudence
Daniel Lemire's blog: A simple algorithm to compute the square root of an integer, byte by byte
A reader asked me for some help in computing (1 – sqrt(0.5)) to an arbitrary precision, from scratch. A simpler but equivalent problem is to compute the square root of an integer (e.g., 2). There are many sophisticated algorithms for such problems, but we want something relatively simple. We’d like to compute the square root bit by bit…
For example, the square root of two is…
- 5 / 4
- 11 / 8
- 22 / 16
- 45 / 32
- 90 / 64
- 181 / 128
- …
More practically, 8-bit by 8-bit, we may want to compute it byte by byte…
- 362 / 256
- 92681 / 65536
- 23726566 / 16777216
- …
How can we do so?
Intuitively, you could compute the integer part of the answer by starting with 0 and incrementing a counter like so:
x1 = 0 while (x1+1)**2 <= M: x1 += 1
Indeed, the square of the integer part cannot be larger than the desired power.
You can repeat the same idea with the fractional part… writing the answer as x1+x2/B+... smaller terms.
x2 = 0 while (x1*B + x2 + 1)**2 <= M*B**2: x2 += 1
It will work, but it involves squaring ever larger numbers. That is inefficient.
We don’t actually need to compute powers when iterating. If you need to compute x**2, (x+1)**2, (x+2)**2, etc. You can instead use a recursion: if you have computed (x+n)**2 and you need the next power, you just need to add 2(x+n) + 1 because that’s the value of (x+n+1)**2 – (x+n)**2.
Finally, we get the following routine (written in Python). I left the asserts in place to make the code easier to understand:
B = 2**8 # or any other basis like 2 or 10 x = 0 power = 0 limit = M for i in range(10): # 10 is the number of digits you want limit *= B**2 power *= B**2 x*=B while power + 2*x + 1 <= limit: power += 2*x + 1 x += 1 assert(x**2 == power) assert(x**2 <= limit) # x/B**10 is the desired root
You can simplify the code further by not turning the power variable into a local variable within the loop. We subtract it from the power variable.
B = 2**8 x = 0 limit = M for i in range(10): limit *= B**2 power = 0 x*=B while power + 2*x + 1 <= limit: power += 2*x + 1 x += 1 limit -= power # x/B**10 is the desired root
The algorithm could be further optimized if you needed more efficiency. Importantly, it is assumed that the basis is not too large otherwise another type of algorithm would be preferable. Using 256 is fine, however.
Obviously, one can design a faster algorithm, but this one has the advantage of being nearly trivial.
Further reading: A Spigot-Algorithm for Square-Roots: Explained and Extended by Mayer Goldberg
Credit: Thanks to David Smith for inspiring this blog post.
Tea Masters: Puerh comparison: Purple Da Yi from 2003 vs '7542' Menghai from 1999


However, the colors of the brews is much more in line with what one would expect:

What about scents and taste?
The scent profile has similarities, which suggest a continuity in the 7542 recipe that has helped establish the fame of Menghai/Da Yi. But the tobacco/leather scent is absent from the 2003 brew. This is a scent that is typical of the traditional CNNP era. And while it's still present, and nicely balanced, in the 1999 brew, it has disappeared from the 2003.


Michael Geist: AI Spending is Not an AI Strategy: Why the Government’s Artificial Intelligence Plan Avoids the Hard Governance Questions

The government announced plans over the weekend to spend billions of dollars to support artificial intelligence. Billed as “securing Canada’s AI Advantage”, the plan includes promises to spend $2 billion on an AI Compute Access Fund and a Canadian AI Sovereign Compute Strategy that is focused on developing domestic computing infrastructure. In addition, there is $200 million for AI startups, $100 million for AI adoption, $50 million for skills training (particularly those in the creative sector), $50 million for an AI Safety Institute, and $5.1 million to support the Office of the AI and Data Commissioner, which would be created by Bill C-27. While the plan received unsurprising applause from AI institutes that have been lobbying for the money, I have my doubts. There is unquestionably a need to address AI policy, but this approach appears to paper over hard questions about AI governance and regulation. The money may be useful – though given the massive private sector investment in the space right now a better case for public money is needed – but tossing millions at each issue is not the equivalent of grappling with AI safety, copyright or regulatory challenges.
The $2 billion on compute infrastructure is obviously the biggest ticket item. Reminiscent of past initiatives to support connectivity in Canada, there may well be a role for government here. However, the private sector is already spending massive sums globally with estimates of $200 billion on AI by next year, leaving doubts about whether there is a private sector spending gap that necessitates government money. If so, government needs to make the case. Meanwhile, the $300 million for AI startups and adoption has the feel of the government’s failed $4 billion Digital Adoption Program with vague policy objectives and similar doubts about need.
But it is the smallest spending programs that may actually be the most troubling as each appear to rely on spending instead of actual policy. The $50 million for creative workers – seemingly more money for Canadian Heritage to dole out – is premised on the notion that the answer to the disruption from AI is skills development. In the context of the creative sector, it is not. Rather, there are hard questions about the use and outputs of copyrighted works by generative AI systems. I’m not convinced that this requires immediate legislative reform given that these issues are currently before the courts, but the solution will not be found in more government spending. There is a similar story with the $50 million for the AI Safety Institute, which absent actual legislation will have no power or significant influence on global AI developments. It is the sort of thing you create when you want to be seen to be doing something, but are not entirely sure what to do.
Most troubling may the smallest allocation of $5.1 million for the Office of the AI and Data Commissioner. First, this office does not exist as it would only be formed if Bill C-27 becomes law. That bill is still stuck in committee after the government instead prioritized Bills C-11 and C-18, letting the privacy and AI bill languish for a year before it began to move in the House of Commons. It could become law in 2025, though there remains considerable opposition to the AI provisions in the bill, which received little advance consultation. Second, $5.1 million is not a serious number for creating a true enforcement agency for the legislation. In fact, the Office of the Privacy Commissioner of Canada estimates it alone needs an additional $25 million. Third, backing enforcement (however meagrely) places the spotlight on the juxtaposition of providing billions in new AI funding while pursuing AI regulation in Bill C-27. Major tech companies have warned that the bill is too vague and costly, mirroring the opposition in Europe, where both France and Germany sought to water down legislation when it became apparent the proposed rules would undermine their domestic AI industries. These are hard legislative choices that have enormous economic and social consequences with government forced to ask to how balance competing objectives and consider which will matter more to AI companies: Canadian government spending or the cost of regulation?
Canada wants to be seen as a global AI leader consistent with its early contributions to the field. But the emerging AI plan sends mixed signals with billions in government spending, legislation that may discourage private sector investment, and avoidance of the hard governance issues. That isn’t a strategy and it isn’t likely to secure an AI advantage.
The post AI Spending is Not an AI Strategy: Why the Government’s Artificial Intelligence Plan Avoids the Hard Governance Questions appeared first on Michael Geist.
OCaml Weekly News: OCaml Weekly News, 09 Apr 2024
- moonpool 0.6
- sqids 0.1.0
- OCaml Retreat at Auroville, India (March 10th - March 15th)
- Miou, a simple scheduler for OCaml 5
- OCaml.org Newsletter: March 2024
- Opam 102: Pinning Packages, by OCamlPro
- dune 3.15
- Ocsigen: summary of recent releases
- Js_of_ocaml 5.7
- Eio Developer Meetings
- Ocaml developer at Routine, Paris
- dream-html 3.0.0
- Other OCaml News
Jesse Moynihan: Tarot Cards are gone
Charles Petzold: Interactive Graphical Arithmetic
CreativeApplications.Net: Spectron – Simon De Mai

Category: NFT
Tags: video
People: Simon De Mai